
The objective of computer vision is to teach computers to see in the same sense that humans do. Over the last few decades, this field has advanced. Vision systems are now ubiquitous, thanks to the advances in image sensor resolution and efficiency, lower-cost compute power and an explosion of data. They’re used for anything from facial recognition to determining which ads you’ll view on your way home from work. It’s an exciting field that has changed virtually every industry and is now facing its most difficult hurdles ever. In this post, we’ll outline a little bit of the nonlinear theory behind it to get you thinking about what happens in your phone, laptop, or car when it ‘sees’ a tree, a face, a text, and a traffic sign. KBV research says the Global Computer Vision Market size is expected to reach $17.9 billion by 2026.
Table of Contents :
- Technologies for Developing Computer Vision
- Google Vision AI
- Microsoft Computer Vision
- Amazon Rekognition
- How Computer Vision Works
- Types in Computer Vision
- Facial Recognition
- Feature Matching
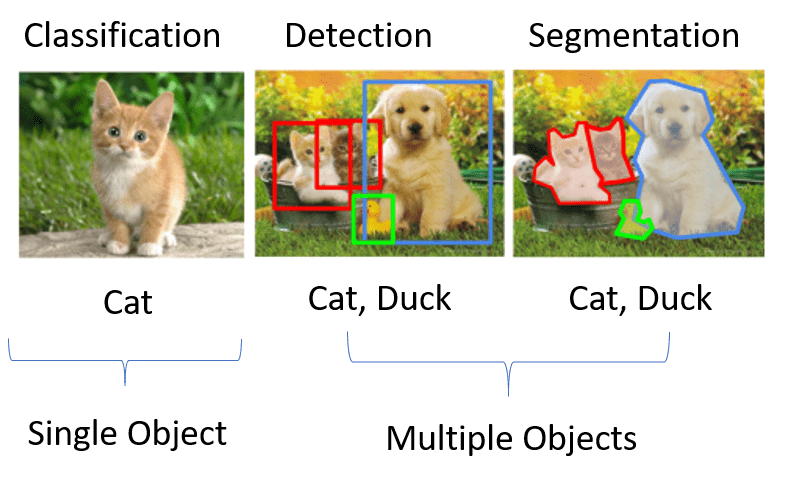
- Image Classification
- Pattern Detection
- Object Detection
- Image Segmentation
- Edge Detection
- What can computer Vision do?
- Scene Reconstructions
- Mask Detection
- Object Classification
- Companies Assist Your Computer Vision
- Tensor Flow
- MATLAB
- Opencv
Technologies for Developing Computer Vision
Google Vision AI
Google Vision is a machine learning system that recognizes objects in photographs. It helps determine and classify the essential ones in a photo, enabling it to perform valuable chores like sorting mail, indexing photos on your hard drive, and searching Google’s image search for related images.
While driving, it can detect landmarks, traffic signals, people, and other vehicles. In addition, Google uses ‘deep learning’ to train tens of billions of images to enable computers to recognize landscapes, animals, objects, and more.
Microsoft Computer Vision
It has enabled computers to comprehend and analyze human languages and visuals. Its work involves Machine Translation, Spoken Language Understanding, Computer Vision, and Natural Language Processing, among other fields.
It’s a system designed to bring computer vision into the mainstream. The goal is to develop a product that will enable the client to assist users in new scenarios such as landmark and image recognition, visual search, video editing, manipulation, object identification, content-based image retrieval, and real-time motion capture for sign language interpretation augmented reality.
Amazon Rekognition
Amazon Rekognition is an image analysis service that is fully managed. You can detect celebrities, places, texts, and license plates in images and detect things. The API from Rekognition allows you to integrate robust picture analysis into your apps swiftly.
Amazon Rekognition is based on Amazon Elastic Compute Cloud (Amazon EC2), a central infrastructure-as-a-service platform from Amazon Web Services.
How Computer Vision Works
Acquire, Process, and Understand are the three basic steps in computer vision.
Obtaining images entails gathering big data sets, 3D imaging in real-time, videos, and photos to begin analysis.
Image processing is a term that refers to the process of not only that, but we can automate the process by vectorizing photos with the help of deep learning models. The first step is for the models to be trained and fed hundreds of pre-defined or tagged images.
Understanding an image is the last and most interpretive stage in classifying objects in a picture.
Source: k21academy
Types in Computer Vision
Facial Recognition
It is a dynamic object detection model that recognizes a human face in a picture and classifies specific individuals. Biometric Update says Facial recognition market to surpass $10B by 2028

Feature Matching
It’s a pattern detection approach that matches recurring themes in photos and uses the data to classify them.
Image Classification
It classifies a bunch of photos into separate groups.
Pattern Detection
It is the technique for finding a pattern of colors, images, and shapes in a snap using visual stimuli.
Object Detection
It can acknowledge specific objects in a single image, such as a football field, a ball, an offensive player, and so on. This model merges X and Y to form a bounding box and captures everything in the image.
Image Segmentation
It split photos into many sections for more analysis.
Edge Detection
It’s a technique for better identifying what’s lying in an image by defining the outside edge of a landscape or an object.
What can Computer Vision do?
Computer vision is a form of device that operates in the same way that the human brain does. Do our brains solve visual object identification due to one general theory, the human brain decodes single items using patterns? Computer vision systems are built on the same principle.
All of today’s computer vision algorithms rely on pattern recognition. For example, scientists use various visual data to train and label objects, such as computer-processed images. In those examples, it locates objects. For example, if we send a billion flower images, the computer will evaluate them and create a floral model. As a result, every time we send them images, the computer can detect a floral image.
Read more: Computer Vision Solutions for Construction Safety – Case Study
In 1950, the computer vision era began, intending to interpret the handwritten and typewritten text. When the task is easy yet requires a lot of work from human operators, the system must provide many data samples for manual analysis. But, thanks to cloud computing and robust algorithms, now we have a lot more processing power. It aids in the resolution of complex challenges.
Deep Learning
Deep learning is a subset of machine learning that uses algorithms to extract insights from data, and it is used in all computer vision algorithms today. On the other hand, machine learning is based on artificial intelligence, which is the backbone for both machine learning and deep learning.

Source: University of Cincinnati
Neural Network
Deep learning makes use of a neural network model. Used to extract data from patterns and data samples. These algorithms are based on connectivity between the cerebral cortex and neurons in the human brain.
The convolution mathematical depiction of biological neurons in the cerebral cortex is the core notion of a neural network, which contains several layers with internal convolution layers. The input data is transferred through the network, designed by convolution layers, and the end in the output layer is a prediction.
Scene Reconstructions
One of the most interesting unsolved problems in computer vision is visual scene reconstruction. The goal of scene reconstruction is to automatically construct a 3D model of a scene from a single camera image or a sequence of images without any prior information about the scene itself. For instance, given a single image of a street with some parked cars, the system should tell us where each car is located, if there are any people or animals on the streets, and even what brand and type of car it is.
Mask Detection
Masked and unconstrained face detection and recognition is an underdeveloped and challenging research area in computer vision. There are many successful techniques for unconstrained face detection and recognition; however, the accuracy of their results degrades rapidly if the face is obscured or occluded. Another difficulty is that there are few training datasets available by which to evaluate these methods. However, a few mobile app businesses have already developed mask detection apps, which detect people wearing masks or not and can be helpful in public transit to avoid covid-19.

Source: lakewood advocate mag
Object Classification
The classical approach to object classification is to train a computer program by manually showing many pictures of objects. The procedure is called supervised learning, and examples of classifiers learned this way are known as classifiers. The process works fine for classifying English words and sentences and even pictures of faces. Still, it fails spectacularly when dealing with classes of images where the concept and features used to describe them change drastically from picture to picture.
Companies assist Your Computer Vision
TensorFlow
It’s a Google-developed open-source framework for executing machine learning, deep learning, and other predictive analytics data. It works with data sets that are placed in a graph as computational nodes. Developers can use tensor flow to create large-scale neural networks with as many layers as they desire, mainly used for creation, prediction, discovery, comprehension, perception, and classifying. Apps like voice search, image recognition, and text-based applications are where it excels. For example, the deep face is a Facebook image recognition software that employs tensor flow to scan photos and is also deployed for speech recognition in Apple’s Siri.
MATLAB
It’s a high-end technical computing language. It integrates programming, visualization, and computing in a user-friendly platform, allowing solutions and problems to be solved in a basic mathematical style. Computation, math, data analysis, visualization, and exploration are just a handful of use cases of MATLAB.
Open CV
It’s an open-source library for image analysis, CCTV footage analysis, video analysis, and other computer vision applications. It’s written in C++ and uses 2500 algorithms to improve performance.
Conclusion
Computer Vision is a dynamic field, using innovative machine learning models to develop tools and software that assist humans in many areas. The latest advancements have been impressive. Unfortunately, we are still a long way from solving computer vision. However, many IT companies have already developed how to adapt CNN-driven Computer Vision systems to real environments. It is expected that this trend won’t change anytime soon.
