



Deploying predictive AI models across a business is no easy feat. The effectiveness of AI depends on the quality of the underlying models. Therefore, it becomes crucial for data scientists and academic researchers to quickly build models with various parameters and identify the most effective ones to deploy them easily and scale them seamlessly.
In its latest blog post, NVIDIA researchers showed how to build speech models with PyTorch Lighting on CPU-powered AWS instances (Grid). PyTorch Lightning is a lightweight PyTorch wrapper designed to make high performance AI research simple. It is an organised PyTorch, which allows users to train their models on CPU, GPUs, or multiple nodes without changing any code.
Grid, which runs on AWS, supports Lightning and classic machine learning frameworks such as TensorFlow, Keras, PyTorch, Sci-Kit, and others. It also helps users to scale the training of models from the NGC catalogue. NGC catalogue is a curated set of GPU-optimised containers for deep learning, visualisation, and high-performance computing (HPC).
PyTorch lightning software and developer environment is available on NGC Catalog. Also, check out GitHub to get started with Grid, NGC, PyTorch Lightning here.
Training AI Models
For building speech models, NVIDIA researchers have used ASR, which transcribes spoken language to text. ASR is a critical component of speech-to-text systems. So, when training ASR models, the goal is to generate text from a given audio input that reduces the word error rate (WER) metric on human transcribed speech. The NGC catalogue contains SOTA pretrained models of ASR.
Further, they use Grid sessions, NVIDIA NeMo, and PyTorch Lightning to fine-tune these models on the AN4 dataset, aka Alphanumeric dataset. Collected and published by Carnegie Mellon University, the AN4 dataset consists of recordings of people spelling out addresses, names, phone numbers, etc.
Here are the key steps to follow when building speech models:
- Create a Grid session optimised for Lightning and pretrained NGC models
- Clone the ASR demo repo and open the tutorial notebook
- Install NeMo ASR dependencies
- Convert and visualise the AN4 dataset (Spectrograms and Mel spectrograms)
- Load and inference a pre-trained QuartzNet model from NGC
- Fine-tune model with Lightning
- Inference and deployment
- Pause session
Create a Grid Session
Users can run Grid sessions on the same hardware they need to scale while providing them with pre-configured environments to iterate the ML process faster. Here, sessions are linked to GitHub, loaded with ‘JupyterHub,’ and can be accessed through SSH and IDE without installing.
Check out the Grid Session tour here. (requires Grid.ai account)
Clone ASR demo repo & open tutorial notebook
Once you have a developer environment optimised for PyTorch Lightning, the next step is to clone the NGC-Lightning-Grid-Workshop repo. After this, the user can open up the notebook to fine-tune the NGC hosted model with NeMo and PyTorch Lightning.
Install NeMo ASR dependencies
Install all the session dependencies by running tools like PyTorch Lightning and NeMo, and process the AN4 dataset. Then, run the first cell in the tutorial notebook, which runs the following bash commands to install the dependencies.
Convert and Visualise the AN4 Dataset
The AN4 dataset contains raw Sof audio files. Convert them to the Wav format so that you can use NeMo audio processing.
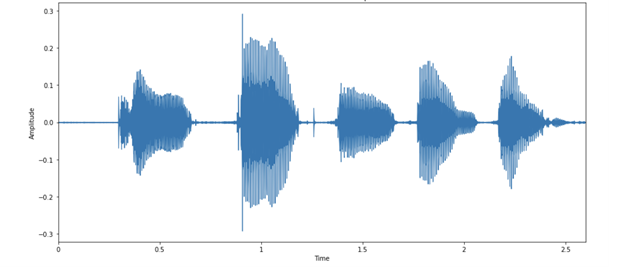
Once processed, you can then visualise the audio example as images of the audio waveform. The below image shows the activity in the waveform that corresponds to each letter in the audio. Each spoken letter has a different “shape.” Interestingly, the last two blobs look relatively similar because they are both the letter N.
Load and Infer Pretrained Model
After you have understood the AN4 datasets, the next step is to use NGC to lead an ASR model to fine-tune with PyTorch Lightning. This model comes with many building blocks and even complete models that you can use for training and evaluation.
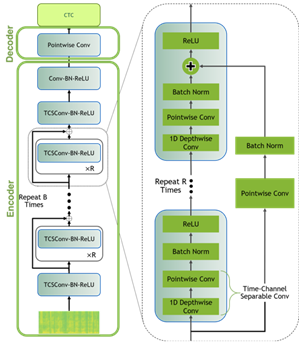
To model the data, the researchers have used a Jasper architecture called QuartzNet. The image below shows that Jasper architecture consists of a repeated block structure that uses 1D convolutions to model spectrogram data.
QuartzNet is a better variant of Jasper as it uses time-channel separable 1D convolutions. As a result, it helps in reducing the number of weights dramatically while keeping similar accuracy.
Fine-tune the Model with Lightning
Once you have a model, you can fine-tune it with PyTorch Lightning. Some of the key advantages include checkpointing and logging by default. Also, you can use 50+ best-practices tactics without needing to modify the model code, including multi-GPU training, model sharding, quantisation-aware training, deep speed, early stopping, mixed precision, gradient clipping, profiling, etc.
Inference and deployment
Once you have a baseline model, the next step is to inference it.
Pause Session
Once you have trained the model, you can pause the session, and all the files you need are required.
Check out all the source codes related to PyTorch Lightning, NGC, and Grid on NVIDIA’s blog.














































































