In Crossplane, the low level primitive for provisioning cloud infrastructure is called managed resource - defined by a CustomResourceDefinition (CRD) with a controller that represents an instance of an offering in the cloud provider. For each service, the CRD type and a slim implementation of a Kubernetes controller have to be written in Go. This process of adding a new resource gets harder when the API of the corresponding cloud provider is not standardized across the board or very imperative - every update requires a dedicated API call.
Since the inception of Crossplane, we have been working on making this as easy as possible by reducing the boilerplate code you need to write and building abstractions on top of the most complex parts of our reconciliation logic. However, as Crossplane enjoys more adoption, we see different use cases from different companies that need support for a specific managed resource that the Crossplane provider doesn’t yet support.
In order to meet the growing demands of the community, we have decided to build tooling on top of the great work the Terraform community has built over the years so that we can target a single consistent interface in the controller code and increase the coverage significantly over a short period of time.
Terrajet is a code generation framework that will generate CRDs and wire up its own generic Terraform controller to reconcile those CRDs, requiring very little manual code to be written and no compromise on Crossplane Resource Model standards - a superset of Kubernetes Resource Model.
In this series, we’ll dive into the architecture of Terrajet and see how different utilities it provides fit together to build thousands of CRDs and controllers.
High Level Overview
At a high level, the providers built with Terrajet call the Terraform CLI in a workspace with curated configuration input in JSON and a TF state file. The Kubernetes controller that calls the Terraform CLI is based on the generic managed reconciler that powers every managed resource in Crossplane by implementing its ExternalClient interface, which is roughly a set of CRUD methods.
There were other competing approaches such as talking with TF provider server directly, bypassing Terraform CLI, but for brevity we’ll not go into details of that choice. You can see the trade-offs we made in the initial design doc here.
While most code generators are in the form of CLI, Terrajet is a set of Go packages we expose to the provider developers for the following reasons:
- They can implement heuristics at any level of the pipeline to streamline the process for their own provider conventions to have less manual code,
- Configuration is accepted as a Go object which they can work with in a statically-typed fashion.
- We are able to ask for functions as part of the configuration and execute them at runtime instead of inventing our own DSL in plain text config files.
- A programming language is easier to work with to configure a codegen pipeline that should cover cases in different providers and resources in each of those providers.
We have 6 top level Go packages, each with a specific purpose but they can be split into two main groups:
Generator Packages:
- types: Generates Go types from a Terraform schema.
- pipeline: Contains file generators and writes files to the disk.
Runtime Packages:
- controller: An ExternalClient implementation to run a managed reconciler.
- resource: Resource abstractions for runtime, i.e. interfaces mostly.
- terraform: Client that’s called by the controller to perform Terraform operations.
In addition, we have a config package that contains configuration objects which are used both in generator and runtime. Provider developers interact mostly with config and pipeline packages; runtime packages are called by the generated code.
In this post, we’ll talk about how types and pipeline packages work and how we can influence their functionality via config package. In the next posts, we’ll dive into the details of controller and terraform packages to see what happens in runtime.
What is needed for a managed resource support?
In order to implement a managed resource, there are roughly three main pieces that you need to write and tie together:
- Representation of a CRD as a Go type.
- Implementation of the ExternalClient interface to get a Kubernetes controller.
- Registration of the CRD and controller with the controller-runtime manager.
In their generator executable, provider developers use the pipeline.Run function with a config.Provider object that has provider configurations which includes resource configurations. It iterates over every resource configuration and writes Go type files and controller setup files that initializes the generic controller as well as the registration files.
The Pipeline
The pipeline package has several generators that are responsible for generating a file. Each of them has a Go template file that they use to render the files but they vary by how they gather the necessary information; some call other packages while others take a few variables from the resource configuration.
In their first iterations, Jet providers used the generators directly, building their own pipeline. Today, you can still do that but most providers use the pipeline.Run function that ties all generators together and runs them in the correct order. All generators write their results in files whose name starts with zz_ to make it more clear that they are generated files.
The generation process results in the following files for, let’s say, AWS VPC resource in EC2 group:
apis/ec2/v1alpha1/zz_vpc_types.go: The VPC Go type and its child types.apis/ec2/v1alpha1/zz_vpc_terraformed.go: The implementation of the resource.Terraformed interface for the VPC type.apis/ec2/v1alpha1/zz_groupversion_info.go: EC2 group metadata used by all types in the v1alpha1 package of the EC2 group.apis/zz_register.go: Lists all the groups and registers their schema with the controller manager in controller-runtime.internal/controller/ec2/vpc/zz_controller.go: Setup function of the generic Terrajet controller for the VPC type.internal/controller/zz_setup.go: Calls all setup functions of all CRD types to register them with the controller-runtime controller manager.
These are all the files that you’d manually write to support a new managed resource. A big difference with manually written managed resources is that instead of each having its own ExternalClient implementation, there is a generic Terrajet controller implementation that each initializes with a different configuration, which we’ll get to in another post.
At this point, all files required for a managed resource are generated. You can create custom resource instances to get your infrastructure provisioned. Now let’s get to the most complex part of the code generation; producing a Go type that can be a Crossplane CRD from Terraform schema.
Generating Custom Resource Definitions
Terraform (TF) requires its providers to publish a schema and a set of functions for CRUD operations that will be run by the TF CLI. In Kubernetes, CRDs define their schema using an OpenAPI specification.
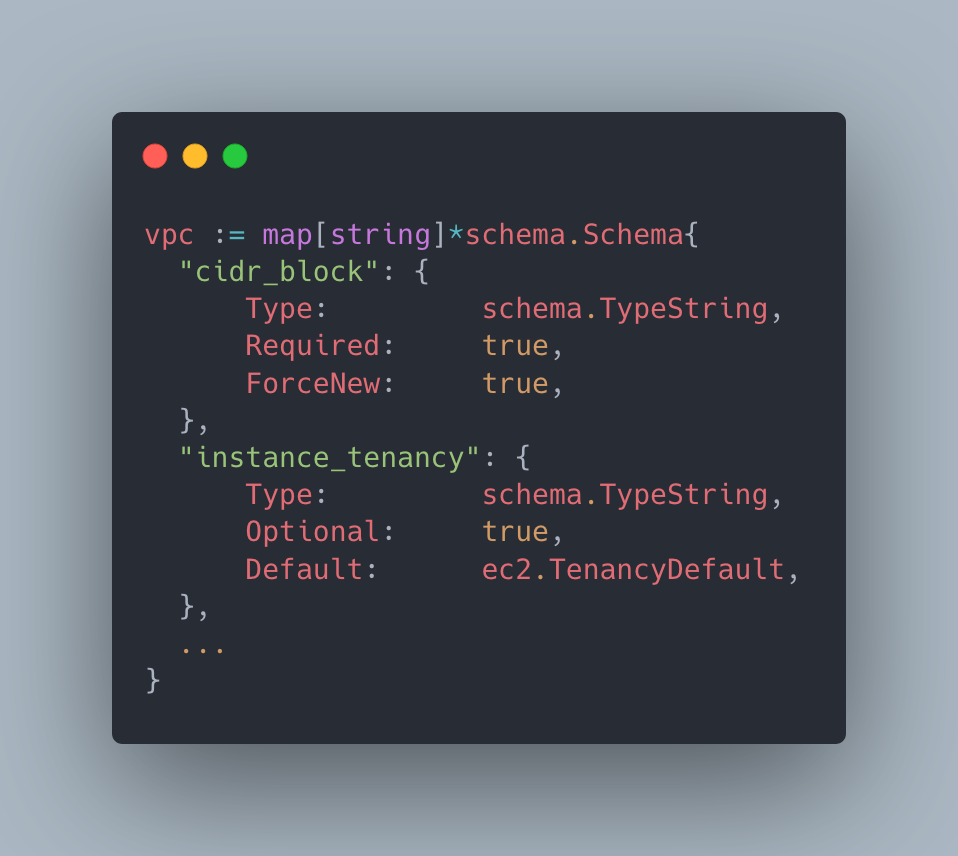

We could possibly generate the CRD YAMLs with OpenAPI schema directly and use a generic struct to work with types in the provider. However, Terrajet generates a Go type that is compatible with controller-runtime utilities, similar to other Crossplane providers because;
- We want Jet-based providers to be as similar to other Crossplane providers as possible to reduce maintenance costs,
- Go types can be imported by other packages without any additional abstraction,
- We feel it’s simpler to understand and work with Go types instead of YAML or OpenAPI spec directly,
- And all the reasons to have strongly typed representations of the data.
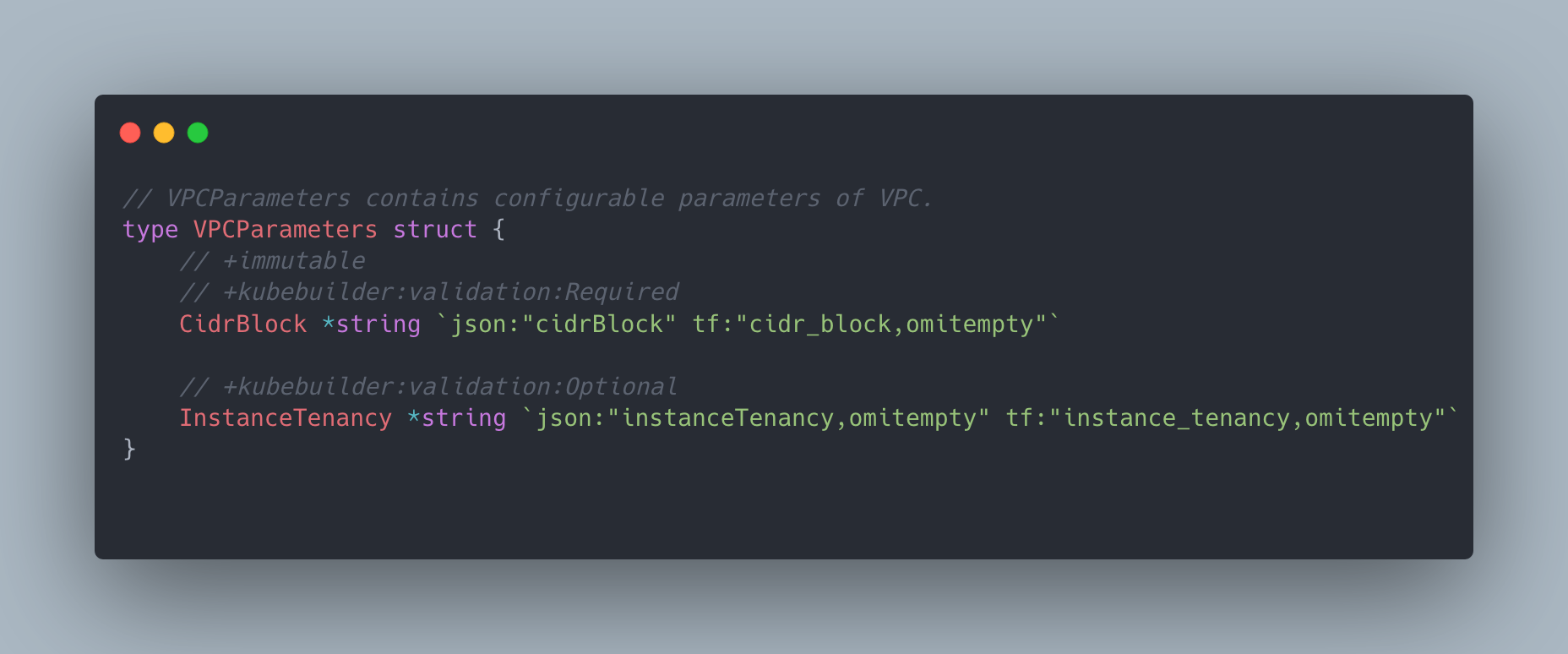
In order to achieve this, Terrajet performs a depth-first search in the schema and builds a type tree using the Go standard library - go/types, the same package used by the Go compiler. The recursive iterator goes through every field and figures out what goes to spec, status, connection details secret or what should be considered as sensitive input and replaced with a SecretKeySelector type.
Some of the challenges with this approach are:
- Kubernetes separates desired and observed state by spec and status top-level fields but TF schema contains all fields under a single schema and differentiates by properties of the field, like “optional”, “computed” etc. This required us to have some heuristics to make the separation. For example, all fields that are “computed and not optional” go to status, “sensitive, computed and not optional” go to connection detail secret and such.
- Kubernetes API conventions require field names to be lower camel case whereas TF uses snake case. Even though the conversion is simple, we need to keep the TF equivalent name for the field as well so that when we convert it to JSON input for TF, we use the original snake case names. To address this, we opted to use jsoniter which allows you to have multiple JSON tags for a field.
- TF schema specification is a key-value map like JSON where there is no concept of “type name”, so we had to generate type names for every attribute whose type is not basic, like string or integer. We name types of complex fields with
<field name>Parameters/<field name>Observation. In case of a collision, which happens frequently with groups with many CRDs, we prefix it with the name of the parent type until it’s unique. - Terraform accepts sensitive data as plain text in input and the TF state file contains sensitive data as well, hence both are sensitive files. But Kubernetes API conventions suggest that sensitive data cannot appear in spec or status of the resources. In order to address these cases:
- The type builder replaces the types of sensitive input fields, like password, with secret reference types that will be resolved for
Secrettype and take the input from there. - The sensitive output fields, like the kubeconfig of the provisioned cluster, are removed from the schema completely and their field paths are printed in the content of a member function of the Go type that will be called in runtime to store and fetch as needed.
- The type builder replaces the types of sensitive input fields, like password, with secret reference types that will be resolved for
- Terraform has no concept of groups in the schema whereas Kubernetes requires grouping of some sort. In many cases, Terraform has the second word in the name implying the group, i.e. "aws_s3_bucket", and we used that calculation as default, there are many cases where this doesn't hold. So, each provider has its own calculation methods and overrides whenever necessary.
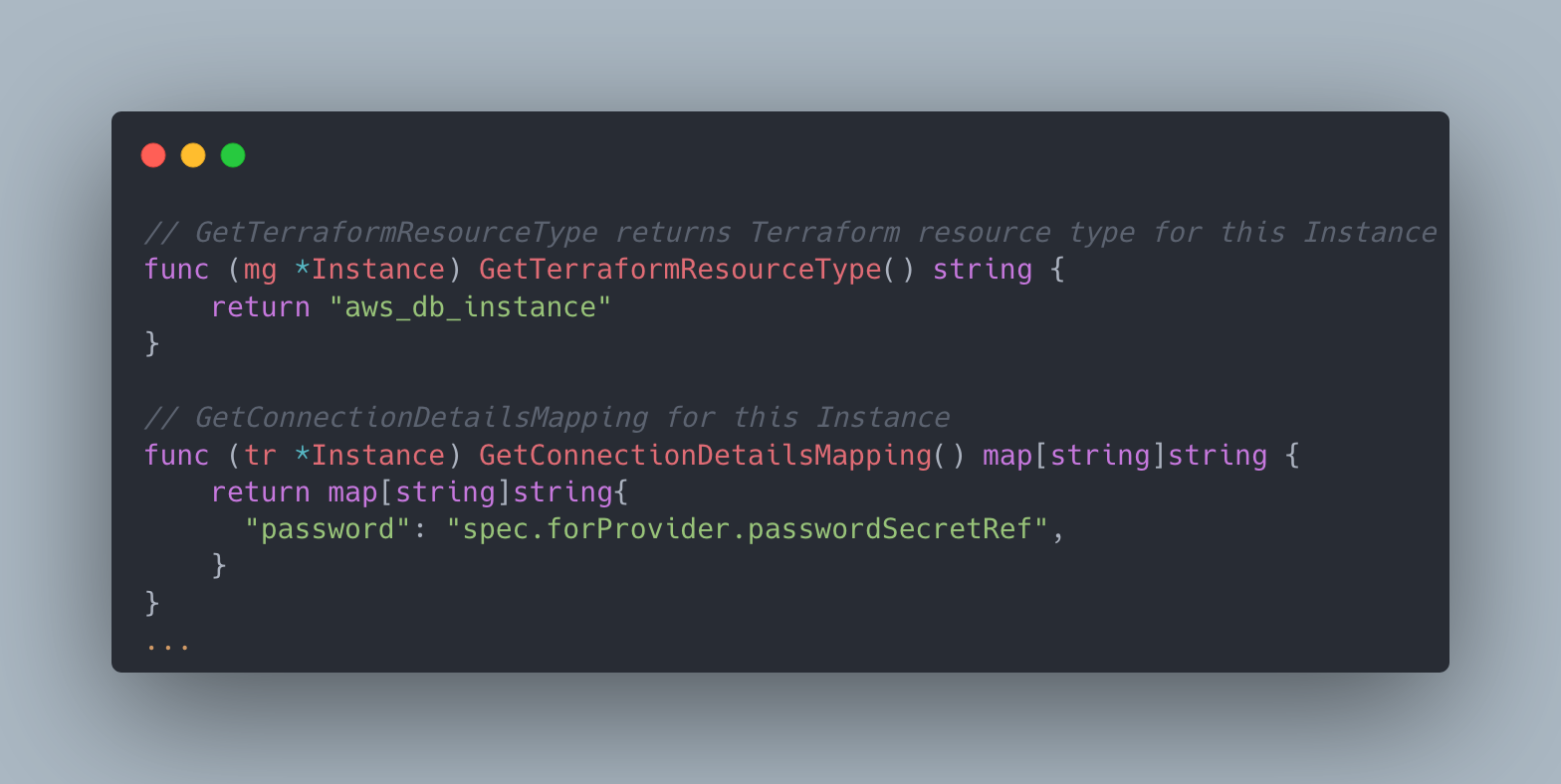
If you noticed, some of the information like which fields are removed from the type cannot be represented as part of the type. In order to store this information, we print an implementation of the interface called resource.Terraformed whose content is populated by the type builder to make that information accessible at runtime.
Now, we have a rough idea about how the Go type for the CRD is generated and files are printed. But life is not perfect and there are some places where we need custom input from users to generate those files correctly.
Resource Configuration
The Crossplane Resource Model (XRM) has features whose implementation require more information than what Terraform’s resource schema provides. For example, when you create an RDS DB Instance, you can reference a VPC object by its Kubernetes name or by a label selector whereas Terraform has a generic information flow mechanism where you need to provide the exact field path of the other resource. Another example is that Crossplane has the notion of external name that is used for naming the resource as well as identifying it in the queries whereas in Terraform the ID of a resource is an internal identifier used in the state file and the name is conveyed with a separate (and indistinguishable) attribute in the HCL input. The provider developers use the config.Resource struct to let Terrajet know what to do in such cases.
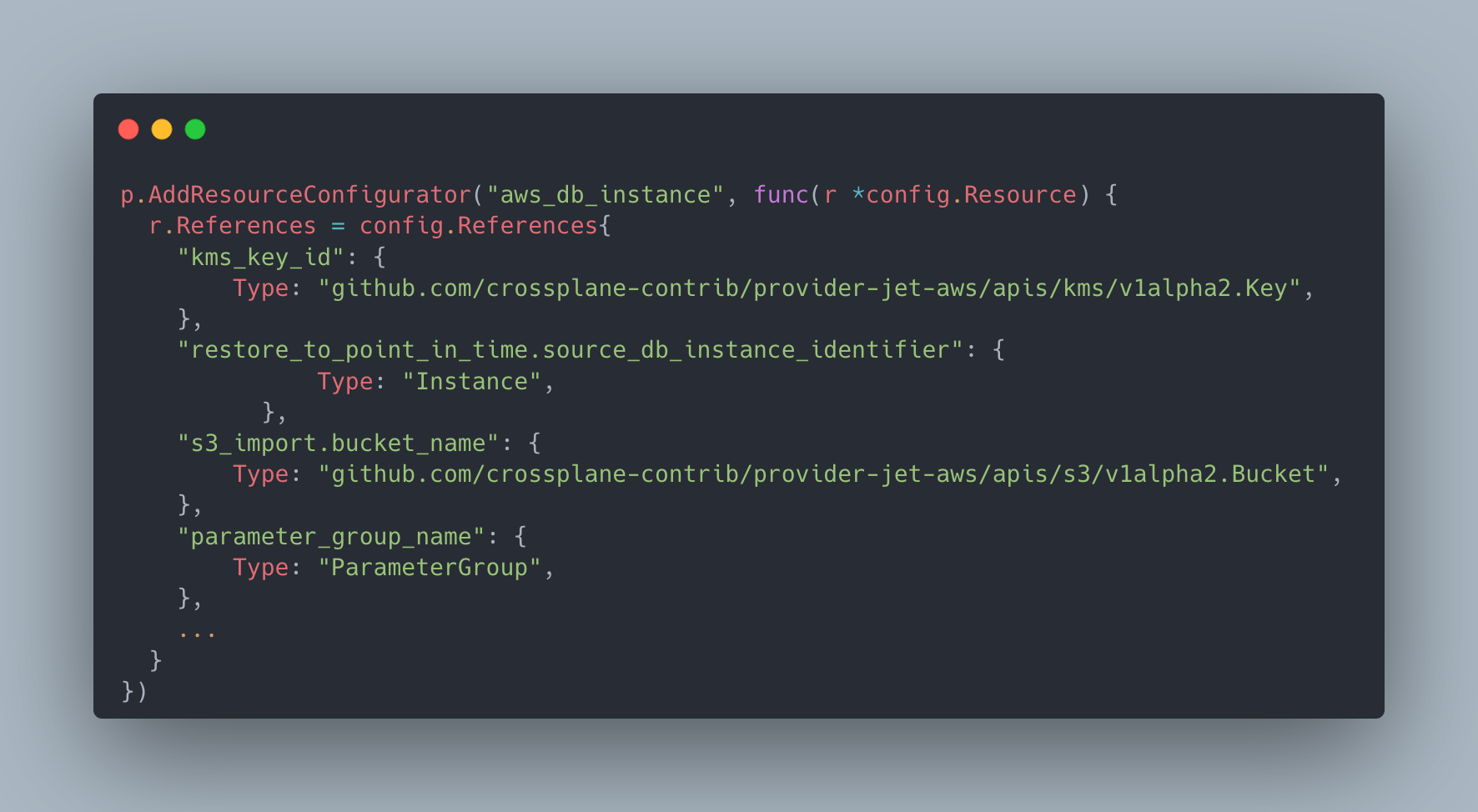
One of the main benefits we get from making Terrajet a set of Go packages instead of a CLI with raw input is that you get to have as much freedom as you’d like when you write these configurations. For example, you can provide actual runtime functions as part of the configuration. The following is an example where GCP returns a set of attributes that is used to connect to GKE cluster but it’d actually be very useful for users to have a single kubeconfig key they can use instead of having to construct it themselves by parsing multiple strings. So, the provider developer can supply a function that constructs that string and add it as an additional field to the connection secret.
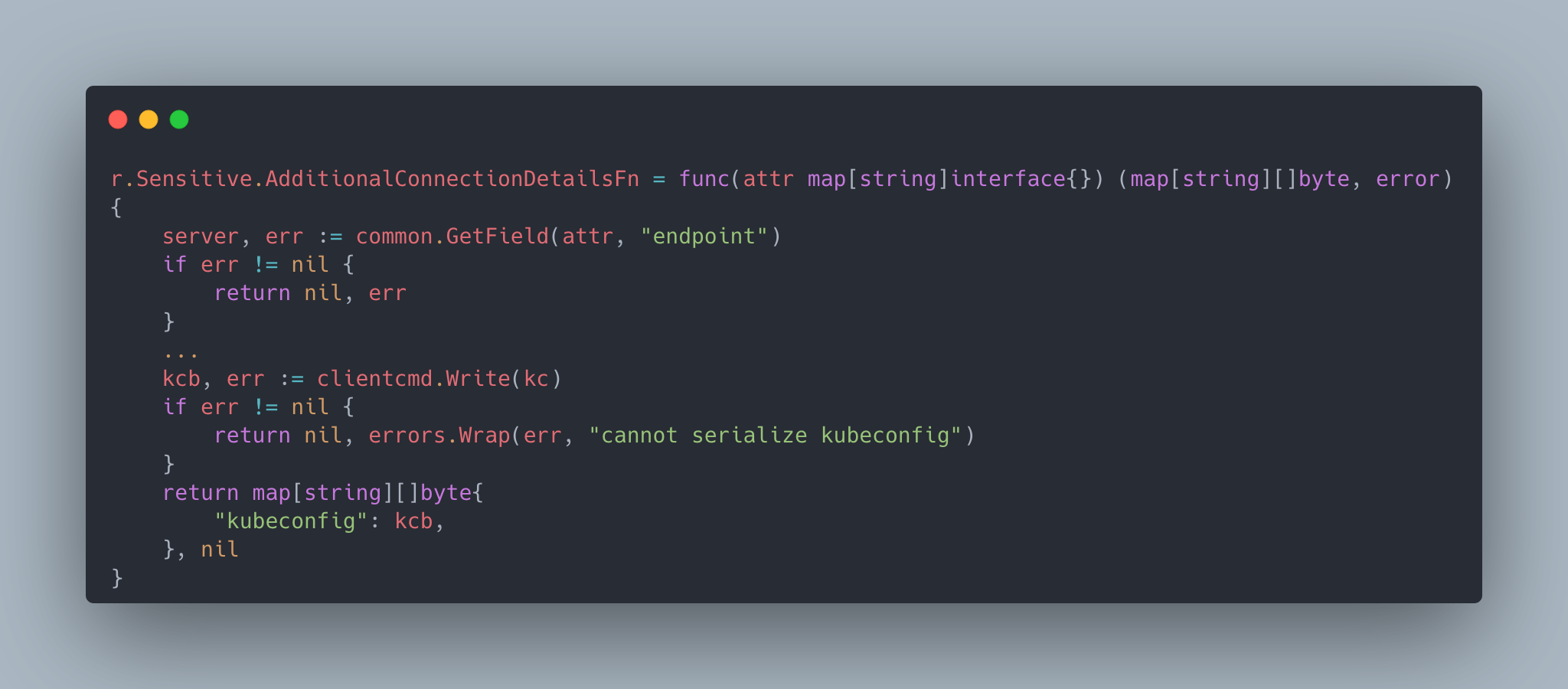
There is also the freedom of having the configuration manipulated at different places before supplying it to Terrajet. There is a default resource configuration constructed for you but it accepts configurator functions. The case where this proves most useful is provider-wide assumptions that you can make and then go granular with additional configurations added for specific resources. For example, you don’t have to add referencer metadata for every “vpc_id” attribute that may exist in some of the 760 CRDs of AWS; you can have a resource configurator function as resource option that’s added to all resources that will add it if it sees that attribute.
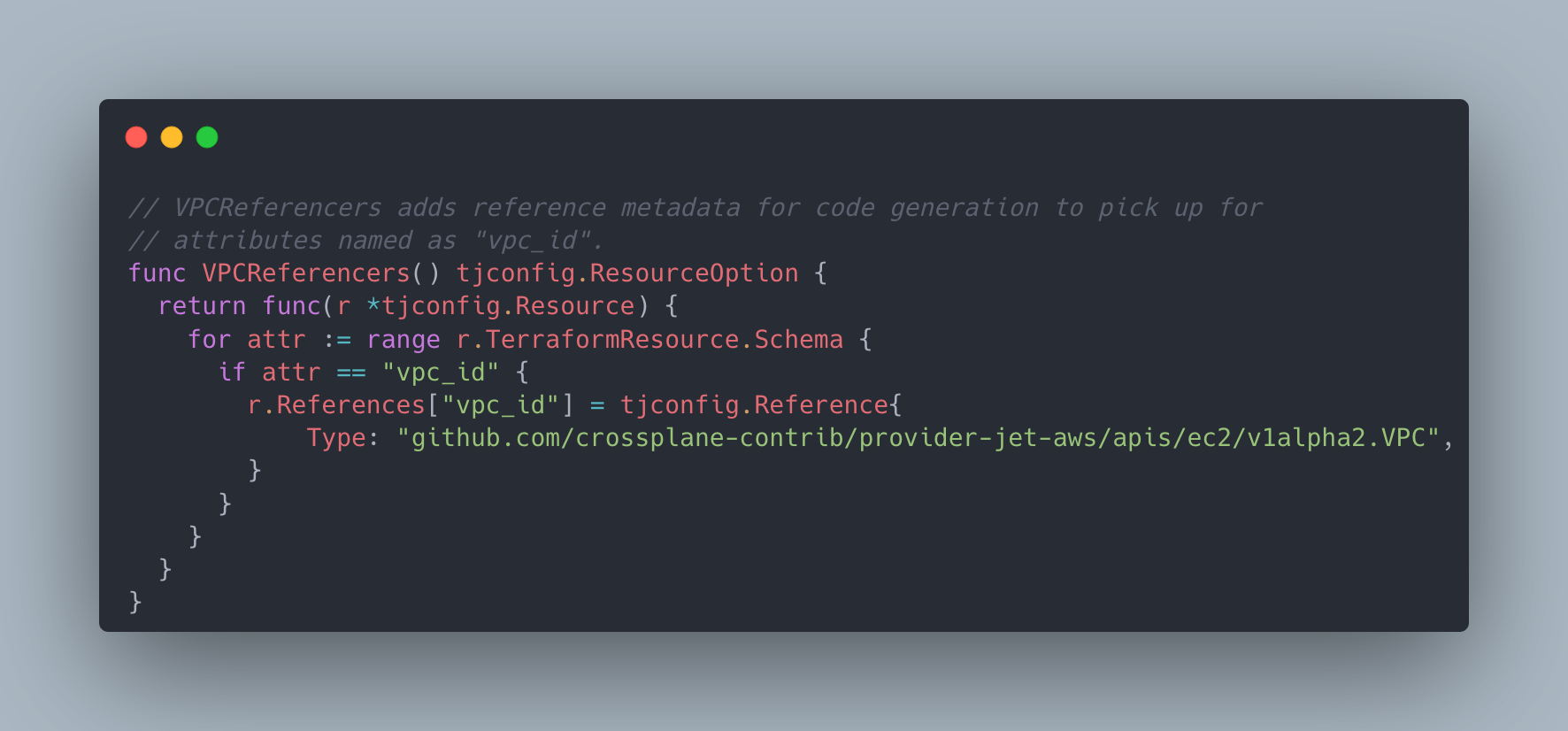
Similarly, you can have as many heuristics as you’d like such as adding a region field to all CRDs, using a single kind name calculator for all resources that can handle provider-specific cases and override its result only in exceptional cases.
We didn’t have to come up with a powerful config format in YAML and you don’t get restricted to having to work in a plain text environment.
Wrapping Up
In this post, we covered the high level structure, pipelines, CRD generation and resource configuration concepts. In the next posts, we dive into how the generic controller works, how we can reproduce TF state whenever needed, the client we built to interact with Terraform CLI and other challenges we faced implementing Terrajet. You can read part two here and part three here.