My Cow Game Extracted Your Facebook Data
The Cambridge Analytica scandal is drawing attention to malicious data thieves and brokers. But every Facebook app—even the dumb, innocent ones—collected users’ personal data without even trying.

For a spell during 2010 and 2011, I was a virtual rancher of clickable cattle on Facebook.
It feels like a long time ago. Obama was serving his first term as president. Google+ hadn’t arrived, let alone vanished again. Steve Jobs was still alive, as was Kim Jong Il. Facebook’s IPO hadn’t yet taken place, and its service was still fun to use—although it was littered with requests and demands from social games, like FarmVille and Pet Society.
I’d had enough of it—the click-farming games, for one, but also Facebook itself. Already in 2010, it felt like a malicious attention market where people treated friends as latent resources to be optimized. Compulsion rather than choice devoured people’s time. Apps like FarmVille sold relief for the artificial inconveniences they themselves had imposed.
In response, I made a satirical social game called Cow Clicker. Players clicked a cute cow, which mooed and scored a “click.” Six hours later, they could do so again. They could also invite friends’ cows to their pasture, buy virtual cows with real money, compete for status, click to send a real cow to the developing world from Oxfam, outsource clicks to their toddlers with a mobile app, and much more. It became strangely popular, until eventually, I shut the whole thing down in a bovine rapture—the “cowpocalypse.” It’s kind of a complicated story.
But one worth revisiting today, in the context of the scandal over Facebook’s sanctioning of user-data exfiltration via its application platform. It’s not just that abusing the Facebook platform for deliberately nefarious ends was easy to do (it was). But worse, in those days, it was hard to avoid extracting private data, for years even, without even trying. I did it with a silly cow game.
Cow Clicker is not an impressive work of software. After all, it was a game whose sole activity was clicking on cows. I wrote the principal code in three days, much of it hunched on a friend’s couch in Greenpoint, Brooklyn. I had no idea anyone would play it, although over 180,000 people did, eventually. I made a little money from the whole affair, but I never optimized it for revenue generation. I certainly never pondered using the app as a lure for a data-extraction con. I was just a strange man making a strange game on a lark.
And yet, if you played Cow Clicker, even just once, I got enough of your personal data that, for years, I could have assembled a reasonably sophisticated profile of your interests and behavior. I might still be able to; all the data is still there, stored on my private server, where Cow Clicker is still running, allowing players to keep clicking where a cow once stood, before my caprice raptured them into the digital void.
To understand why withdrawing data was the default behavior in Facebook apps, you have to know something about how apps get made and published on Facebook. In 2007, the company turned its social-network service into an application platform. The idea was that Facebook could grow its number of users and the time they spent engaged by allowing people and organizations to build services overtop of it. And those people and organizations would benefit by plugging into a large network of users, whose network of friends could easily be made a part of the service, both for social interaction and viral spread.
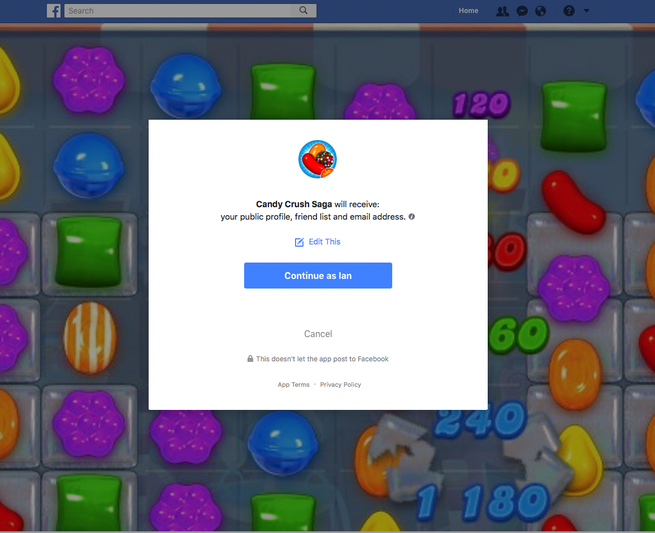
When you access an app on Facebook’s website, be it a personality-quiz, a game, a horoscope, or a sports community, the service presents you with an authorization dialog, where the specific data an app says it needs is displayed for the user’s consideration. That could be anything from your name, friend list, and email address, to your photos, likes, direct messages and more.
The information shared with an app by default has changed over time, and even a savvy user might never have known what comprised it. When I launched Cow Clicker in 2010, it was easier to acquire both “basic” information (name, gender, networks, and profile picture) and “extended” user information (location, relationship status, likes, posts, and more). In 2014, Facebook began an app review process for information beyond that which a user shared publicly, but for years before that, the decision was left to the user alone. This is consistent with Facebook’s longstanding, official policy on privacy, which revolves around user control rather than procedural verification.
App authorizations are not exceptionally clear. For one thing, the user must accept the app’s request to share data with it as soon as they open it for the first time, even before knowing what the app does or why. For another, the authorization is presented by Facebook, not by the third party, making it seem official, safe, and even endorsed.
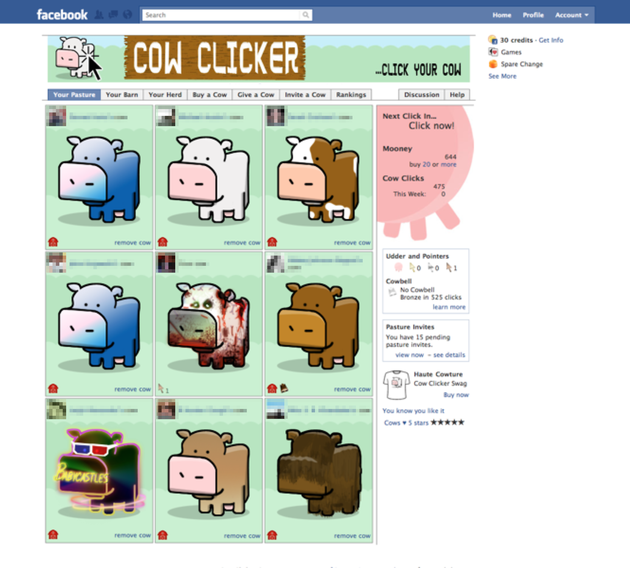
The part of the Facebook website where apps appear, under the blue top navigation (as seen above), introduces further confusion. To the average web user, especially a decade ago, it looked like the game or app was just a part of Facebook itself. The page is seamless, with no boundary between the site’s navigational chrome and the third-party app. If you look at the browser address bar while using a Facebook app on the website, the URL begins with “apps.facebook.com,” further cementing the impression that the user was safely ensconced in the comforting, blue cradle of Facebook’s care.
That’s not what really takes place. When a user loads an app, Facebook’s servers pass those requests to a remote computer, where the individual or company that made the app hosts their services. The app sends its responses to Facebook, which formats and presents them to the user, as if they were inside of Facebook itself.
The authorization process happens once, the first time the app is accessed for a specific user. After that, every time the user loads the app, Facebook sends it a payload of basic user data to facilitate the app’s operation (additional data can be requested separately when needed). For years, these transmissions were even conducted unencrypted, until Facebook required apps to communicate with its service over a secure connection.
Beyond its own terms of service for applications, which many developers probably didn’t read or feel compelled to heed, Facebook “secured” user data shared with third-parties by requiring every app to publish a privacy policy. Because data sharing was seen as a form of user-control, not corporate policy, Facebook doesn’t appear to review platform-developer privacy policies. As far as I can tell, all the platform did was to insure that accessing the URL for an app’s privacy policy didn’t result in a page-not-found error. Facebook was checking that privacy policies existed as reachable web pages, not that they existed as privacy policies, let alone policies that provided any specific protections. And besides, users probably never read the policies, which were linked unassumingly from the application-permissions interface. They might easily, and reasonably, have assumed that Facebook was simply reiterating its own privacy policy when presenting new access to an app. They would have been wrong.
In essence, Facebook was presenting apps as quasi-endorsed extensions of its core service to users who couldn’t have been expected to know better. That might explain why so many people feel violated by Facebook this week—they might never have realized that they were even using foreign, non-Facebook applications in the first place, let alone ones that were siphoning off and selling their data. The website always just looked like Facebook.
In the case of Cow Clicker, which only ever aimed to let people click on pictures of cows, I was able to access two potentially sensitive pieces of data without even trying.
The first is a player’s Facebook ID. This is a numeric, unique identifier attached to every Facebook account. Once I have your Facebook ID, I can look up your profile programmatically, or I can just load it in the public website by appending it to “facebook.com”—Mark Zuckerberg’s is 4.
These days, Facebook generates a unique, app-specific ID for each user, in order to prevent an app from connecting someone directly to Facebook profiles. But back in Cow Clicker’s heyday of 2010, Facebook didn’t do this, and every app got your actual ID. Those data could be correlated against other information—data collected from Facebook, fashioned by the app, or acquired elsewhere. Because I collected and stored my users’ true Facebook IDs to be able to count their clicks and build their pastures and the like, I still have them, and, in theory, I could use them nefariously. A 2014 terms-of-service update prohibits some of that activity, but not everyone cares about violating the Facebook terms of service.
The second type of information is a piece of profile data Cow Clicker received without asking for it. Back in 2010, Facebook still allowed users to join “networks”—affiliations like schools, workplaces, and organizations. In some cases, those affiliations required authorization, for example having an email address at a domain that corresponds with a university. Over time, verification became less important to Facebook, and now users can affiliate with schools or workplaces arbitrarily. The less friction, the more data.
In 2010, on my friend’s couch in Brooklyn, I noticed that Facebook was shipping user affiliation data over the wire to me, so I decided to store it. Facebook allowed apps to store data for which user permission was granted, but urged developers not to request or store more than it needed to operate. Putting affiliation data in the Cow Clicker database allowed me to provide leaderboard rankings by network, allowing my players to compete for clicks with their work colleagues or classmates.
That’s neither a terribly interesting feature nor a particularly wicked one. But because I stored the numerical identifiers for user affiliations, I still have them. Until 2016, I could use a database-query tool called FQL, Facebook Query Language, to retrieve the details of those networks, and correlate them back to my users. Had I wanted to, I could have recombined that information with other data and used it for retargeting.
Cow Clicker’s example is so modest, it might not even seem like a problem. What does it matter if a simple diversion has your Facebook ID, education, and work affiliations? Especially since its solo creator (that’s me) was too dumb or too lazy to exploit that data toward pernicious ends. But even if I hadn’t thought about it at the time, I could have done so years later, long after the cows vanished, and once Cow Clicker players forgot that they’d ever installed my app.
This is also why Zuckerberg’s response to the present controversy feels so toothless. Facebook has vowed to audit companies that have collected, shared, or sold large volumes of data in violation of its policy, but the company cannot close the Pandora’s box it opened a decade ago, when it first allowed external apps to collect Facebook user data. That information is now in the hands of thousands, maybe millions of people.
To be honest, I’m not even sure I know what the Facebook platform’s terms of service dictated that I do with user data acquired from Facebook. Technically, users could revoke certain app permissions later, and apps were supposed to remove any impacted data that they had stored. I doubt most apps did that, and I suspect users never knew—and still don’t know—that revoking access to an app they used eight years ago doesn’t do anything to reverse transmissions that took place years ago.
As Jason Koebler put it at Motherboard, it’s too late. “If your data has already been taken, Facebook has no mechanism and no power to make people delete it. If your data was taken, it has very likely been sold, laundered, and put back into Facebook.” Indeed, all the publicity around Facebook’s Cambridge Analytica crisis might be sending lots of old app developers, like me, back to old code and dusty databases, wondering what they’ve even got stored and what it might yet be worth.
Recommended Reading



Facebook’s laissez-faire openness surely contributed to the data-extraction free-for-all that’s playing itself out now via the example of Cambridge Analytica. But so did its move-fast-and-break-things attitude toward software development. The Facebook platform was truly a nightmare to use and to maintain. It was built like no other software system then extant, and it changed constantly—regular updates rolled out weekly. Old code broke, seemingly for no good reason. Some Facebook app developers were dishonest from the start, and others couldn’t help themselves once they saw the enormous volume of data they could slurp from millions or tens of millions of Facebook users. But many more were just struggling to eke out a part of their living in an ecosystem where people might discover them.
Millions of apps had been created by 2012, when I hung up my cowboy hat. Not only apps apparently designed with duplicity in mind, like Aleksandr Kogan’s personality-quiz, which extracted data that was then sold to Cambridge Analytica. But hundreds of thousands of creators of dumb toys, quizzes, games, and communities that might never have intended to dupe or violate users surely did so anyway, because Facebook rammed their data down our throats. On the whole, none of us asked for your data. But we have it anyway, and forever.