서버에 걸리는 부하, 추측하지 말고 계측하자
by injae Kim
서버에 걸리는 부하, 추측하지 말고 계측하자
주니어 백엔드 개발자인 라이언은 자신이 개발하고 배포한 서비스가 서버 위에서 아무 문제 없이 잘 돌아가는 것을 보고 매우 만족하는 평화로운 나날을 보내고 있었습니다.
어느날, 라이언이 속한 개발팀의 Slack 채널에 금요일 퇴근 직전 경고 메시지가 날아오게 됩니다. “로그인이 안돼요!” “서버 지금 이상해요!”
주니어 백엔드 개발자인 라이언은 소중한 금요일 밤을 수호하기 위해 신속하게 문제를 해결하고 퇴근하고자 합니다.
이때, 서버에 어떤 문제가 발생했는지를 짐작이나 추측이 아닌, 어떻게 하면 정확하게 계측하고 분석할 수 있을까요?
오늘은 서버에 걸리는 부하를 리눅스의 커널에 대한 이해를 기반으로 계측하는 방법과 그 원리에 대해서 알아보겠습니다.
이 글은 대규모 서비스를 지탱하는 기술 과 24시간 365일 서버/인프라를 지탱하는 기술 책을 읽고 혼자만 알기엔 너무 좋은 내용이 있어서 공유를 목적으로 작성하게 되었습니다.
서버야 어디가 아프니?
 |
 |
|---|---|
| 네트워크 부하 분산 | 서버 자체의 성능 부하 |
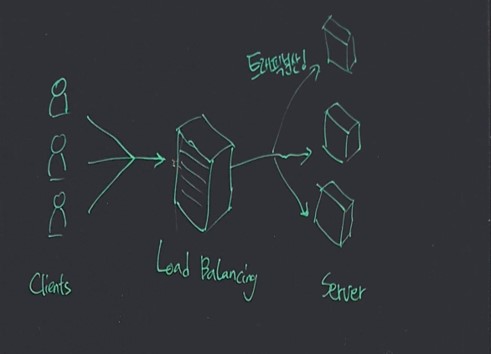
서버에 걸리는 부하의 정체를 파악해서 해결하려면, 먼저 서버에 어떤 부하가 걸리는지 부터 알아야 합니다.
일반적으로 서버에 걸리는 부하는 크게 네트워크 부하 와 서버의 성능 부하 로 분류됩니다.
네트워크 부하는 말 그대로, 서버에 접속하려는 사람이 폭발적으로 증가하여 트래픽이 급증한 경우의 네트워크에 걸리는 부하를 말합니다.
이러한 경우 서버 앞단에서 트래픽 자체를 분산시켜주는 로드밸런서를 사용하거나 서버의 대수를 더 늘리는 방식으로 해결할 수 있습니다.
하지만, 애초에 우리의 서버가 서버 자체의 성능을 100% 발휘하고 있지 않다면 서버의 대수를 늘리거나 로드밸런서를 사용해도 그 효율이 매우 낮을 것 입니다.
따라서 로드밸런서 등으로 네트워크 부하에 대한 분산을 고려하기 전에, 서버 1대가 자신의 성능을 잘 발휘하고 있는지 부터 확인해 볼 필요가 있죠.
그렇다면, 네트워크 부하를 제외한 서버에 걸리는 부하는 무엇이 있을까요? 바로 알아보겠습니다.
단일 서버의 병목 원인 조사
단일 서버에 걸리는 부하의 원인은 크게 2가지로 분류됩니다.
- CPU 부하
- I/O 부하
CPU 부하가 높은 경우는 서버에서 실행되고 있는 프로그램 자체의 연산량이 많은 경우나 프로그램에 오류등이 발생한 경우 입니다.
이러한 경우에는 프로그램에서 발생하는 오류를 제거하거나 알고리즘의 시간, 공간 복잡도를 개선하여 대응할 수 있습니다.
I/O 부하가 높은 경우는 서버에서 실행되고 있는 프로그램의 입출력이 많거나, DB나 하드디스크 등의 저장장치로의 접근이 많아 스왑이 발생하는 경우가 대부분 입니다.
이러한 경우 특정한 프로세스가 극단적으로 메모리를 소비하고 있는지 확인한 후, 프로그램 자체에 오류가 있다면 프로그램을 개선하거나 탑재된 메모리의 용량 자체가 부족한 경우 램을 추가하여 메모리를 증설하는 방법으로 대응할 수 있습니다.
저장장치나 하드디스크로의 입출력이 빈번하게 발생하는 경우 또한 메모리를 증설하거나, 메모리 증설로 대응할 수 없는 경우는 데이터 자체를 분산 (샤딩이나 파티셔닝) 하거나 캐시서버등을 도입하는 방안을 고려해볼 수 있습니다.
단일 서버에서 발생하는 부하의 원인을 간단하게 살펴보았는데요, 그렇다면 우리는 이러한 부하를 어떻게 측정할 수 있을까요?
답은 리눅스 운영체제의 커널에 있습니다.
운영체제에서 프로세스를 실행하는 방식과 부하의 측정
 |
|---|
| 프로세스 멀티태스킹 |
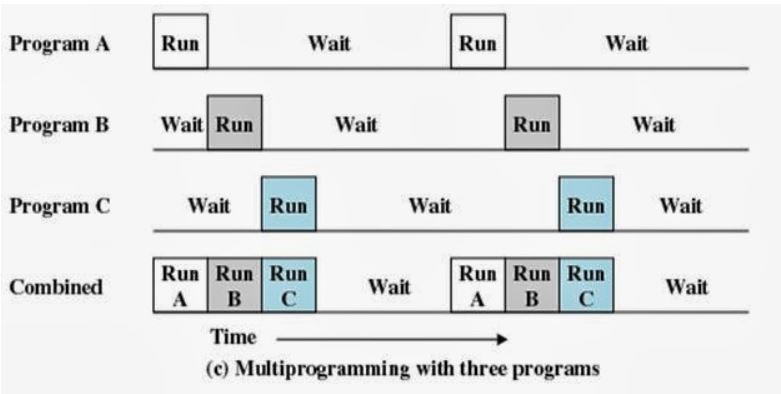
리눅스나 윈도우 등의 운영체제 에서는, 동시에 여러 프로세스들을 처리하기 위해 멀티 태스킹 방식을 사용합니다.
CPU나 디스크 등의 유한한 하드웨어에서 여러 프로세스들을 동시에 처리하기 위해, 매우 짧은 시간 간격으로 여러 프로세스들을 돌아가면서 처리하는 방식이죠!
이러한 멀티태스킹 방식에서, 처리해야 할 프로세스가 점점 많아지면 어떻게 될 까요? CPU 를 사용하고 싶어 대기하고 있는 프로세스들이 점점 쌓이게 되겠죠!
이렇게 CPU 를 사용하려고 기다리고 있는 프로세스 를 운영체제 에서는 Load average (평균 부하) 라고 정의합니다.
CPU를 사용하려고 기다리고 있는 프로세스가 많을 수록, CPU는 바쁘다는 의미이고 결국 시스템에 걸리는 부하가 크다는 뜻이겠죠.
리눅스에선 top 명령어에서 이러한 Load average 를 확인할 수 있습니다.
$ top
load average : 0.70, 0.66, 0.58 # 1분, 5분, 15분 동안 대기하고 있던 태스크의 평균 수
top 명령어로 1분, 5분, 15분 동안 몇개의 태스크가 CPU를 사용하려고 기다리고 있는 대기 상태에 있었는지 를 알 수 있습니다.
따라서 load average 가 높은 상황은 지연되는 태스크가 많다는 것을 의미합니다.
하지만, load average 는 단순히 지연되는 태스크의 수 를 의미하며, CPU 부하가 높은지 I/O 부하가 높은지 까지는 상세하게 알 수 없습니다.
따라서 조금 더 자세히 부하의 원인을 살펴볼 필요가 있습니다.
프로세스의 상태와 Load average 가 보고하는 부하의 정체
앞에서 load average 는 CPU 를 기다리는 태스크의 수 라고 했는데요, 태스크의 상태를 조금 더 자세히 살펴보겠습니다.
운영체제에 의해서 프로그램이 실행되는 단위를 태스크 혹은 프로세스 라고 합니다. (넓은 의미에서 같다고 생각하겠습니다)
리눅스의 커널은 이러한 프로세스들을 CPU 에 어느순서로 할당할 지 스케쥴링 하는데요, 이때 프로세스를 상태 별로 나누어서 관리합니다.
예를들어, CPU가 할당되기를 기다리는 상태의 프로세스 들 과 I/O 완료를 기다리고 있는 프로세스들을 묶어서 관리하죠.
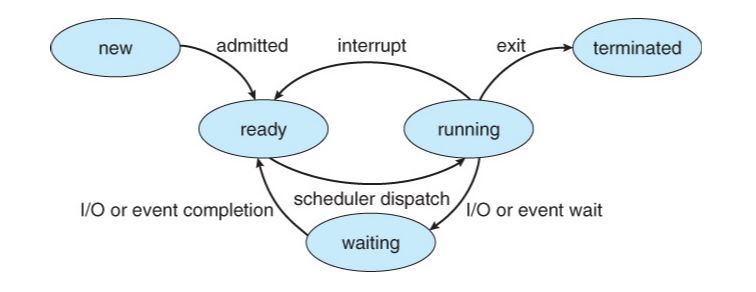
프로세스의 상태 와 의미는 다음과 같습니다.
프로세스의 상태와 의미
 |
|---|
| 프로세스 상태 변화 |
| 상태 | 설명 |
|---|---|
| TASK_RUNNING | 실행 가능한 상태, CPU 가 시간이 나면 실행이 언제든지 가능한 상태 |
| TASK_INTERRUPTIBLE | 중단 가능한 대기 상태, 사용자의 입력 대기 등의 상태 |
| TASK_UNINTERRUPTIBLE | 중단 불가능한 대기 상태, I/O 완료 대기 등의 상태 |
| TASK_STOPPED | 중지 시그널을 받아서 중단된 상태, resume 될 때 까지 스케쥴링에 미포함 |
| TASK_ZOMBIE | 좀비 상태, 자식 프로세스가 종료된 후 부모 프로세스로 반환되지 않은 상태 |
운영체제를 공부해보신 분 이라면 매우 익숙한 그림이죠?
놀라운 점은, 운영체제 시간에 배웠던 이런 개념이 실제로 커널의 load average 측정에 그대로 구현되어 있다는 점 입니다!
실제로 리눅스 커널의 Load Average 를 계산하는 커널 코드를 확인해보겠습니다.
리눅스 커널의 Load Average 를 계산하는 커널 코드
CPU 는 일정 시간 간격으로 인터럽트를 발생시켜 실행중인 프로세스를 바꾸는데요, 이를 타이머 인터럽트 라고 하며 CentOS 5 에서는 4ms 간격으로 인터럽트가 발생되게 설정되어있습니다.
타이머 인터럽트가 발생할 때 마다, CPU 의 Load Average 값이 계산되게 됩니다.
Load Average 는 인터럽트 시 실행가능 상태에 있는 태스크 수 와 I/O 대기 상태의 태스크 수 를 계산합니다.
Github 공개되어 있는 리눅스 커널 소스코드 중 timer.c 의 calc_load() 함수에서 load average 를 실제로 리눅스 커널이 계산하는 방법을 확인할 수 있습니다.
// kernel / timer.c
unsigned long avenrun[3];
static inline void calc_load(unsigned long ticks)
{
unsigned long active_tasks; /* fixed-point */
static int count = LOAD_FREQ;
count -= ticks;
// 타이머 인터럽트 발생 시
if (count < 0) {
// 타이머 초기화
count += LOAD_FREQ;
// active 상태의 task 수 계산
active_tasks = count_active_tasks();
// 1분, 5분, 15분 당 load average 를 계산하여 avenrun[] 배열에 저장
CALC_LOAD(avenrun[0], EXP_1, active_tasks);
CALC_LOAD(avenrun[1], EXP_5, active_tasks);
CALC_LOAD(avenrun[2], EXP_15, active_tasks);
}
}
전역변수 avenrun 배열에 active_tasks 의 수를 저장하고 있는것을 볼 수 있죠! 이는 리눅스에서 top 명령어를 실행하면 load average 가 1분, 5분, 15분 동안 측정된 결과값을 출력하는데, 왜 이렇게 출력되는지도 이제 알 수 있습니다.
그렇다면, 조금더 자세히 들어가서 load average 가 측정하는 active_tasks 란 구체적으로 어떤 상태의 태스크 들을 의미할까요? 위의 calc_load() 함수에서 호출하고 있는 count_active_tasks() 함수에 그 힌트가 있습니다.
// kernel / timer.c
static unsigned long count_active_tasks(void)
{
struct task_struct *p;
unsigned long nr = 0;
read_lock(&tasklist_lock);
for_each_task(p) {
// TASK_RUNNING 상태와 TASK_UNINTERRUPTIBLE 상태의 프로세스의 수 를 센다
if ((p->state == TASK_RUNNING ||
(p->state & TASK_UNINTERRUPTIBLE)))
nr += FIXED_1;
}
read_unlock(&tasklist_lock);
return nr;
}
위의 소스코드 에서, 앞서 살펴봤던 프로세스 상태 중 RUNNING 과 UNINTERRUPTIBLE 상태의 프로세스의 수 를 계산하고 있는 것을 확인할 수 있습니다!
즉, Load Average 의 정체는 커널이 CPU 사용 대기중인 프로세스와 I/O 완료를 대기하고 있는 프로세스의 수 를 계산하여 1분, 5분, 15분 단위로 합산한 값 임을 알 수 있습니다.
드디어 Load Average 의 정체를 정확하게 알았네요!
더 자세히 알려줘! CPU 사용률과 I/O 대기율
앞에서 Load Average는 CPU 사용 대기중인 프로세스와 I/O 완료를 대기하고 있는 프로세스의 수 라는 사실을 알아보았는데요, 이는 시스템 부하의 원인이 대부분의 경우 CPU 나 I/O 에 있음을 나타내고 있습니다.
Load Average 로 시스템에 과부하가 걸리고 있다는 사실을 알게된 후에는, 한단계 더 나아가 CPU 와 I/O 중 어떤 부분에서 부하가 걸리는 지를 조사해야 합니다.
어떤 시스템 에서 CPU 부하가 큰 경우를 CPU 바운드한 시스템이라고 하며, I/O 부하가 큰 경우를 I/O 바운드 한 시스템 이라고 말합니다.
시스템에서 걸리는 CPU, I/O 바운드 부하의 경우 sar(system activity reporter) 명령어로 확인할 수 있습니다.
sar 명령어를 사용하여 CPU 바운드와 I/O 바운드의 경우에서 어떤 차이점이 있는지 알아보겠습니다.
CPU 바운드 인 경우
 |
|---|
| CPU 의 사용자 모드, 시스템 모드 |
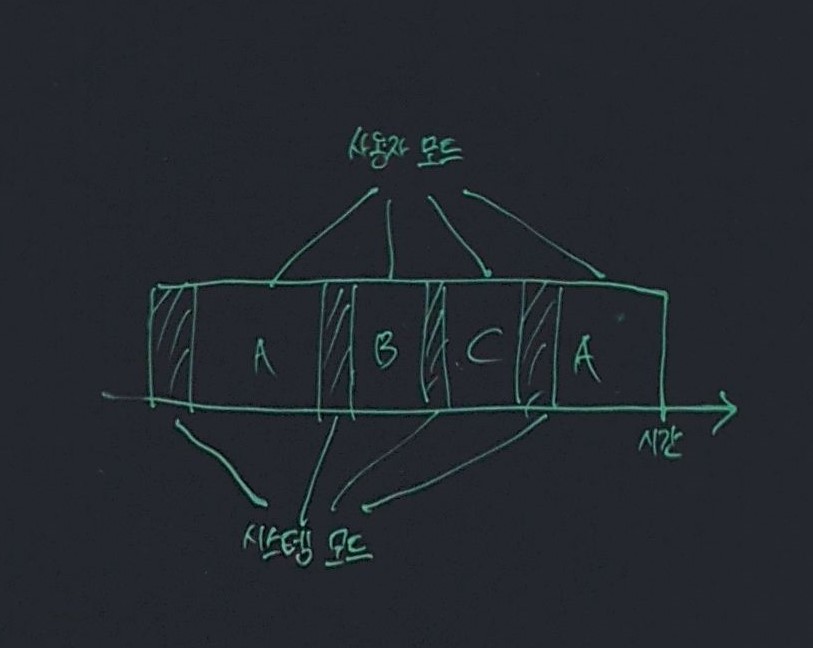
CPU 는 위의 사진처럼 사용자 모드와 시스템 모드 로 나뉘어 집니다.
사용자 모드는 사용자 프로그램이 동작할 때의 CPU 모드이며 시스템 모드는 커널이 동작할 때의 CPU 모드 입니다.
sar 명령어로 CPU 바운드한 시스템에서의 CPU 사용률을 확인해보겠습니다.
$ sar
00:00:01 CPU %user %nice %system %iowait %idle
00:10:01 all 59.42 0.00 1.50 0.00 49.07
00:20:01 all 47.30 0.00 1.36 0.00 53.33
00:30:01 all 52.41 0.00 1.51 0.02 43.54
00:40:01 all 45.20 0.00 1.55 0.00 41.33
sar 명령어를 사용하면 부하를 시간 경과 별로 확인할 수 있어 매우 편리합니다.
위의 결과에서 %user 는 사용자 모드에서의 CPU 사용률 을 나타내며 %system 은 시스템 모드에서의 CPU 사용률 입니다.
이때 %user 이 %system 이나 %iowait 에 비해 월등히 높은 것을 확인할 수 있는데, 이는 사용자 모드의 CPU 사용률이 높다는 것 을 의미합니다.
Load Average 가 높고 사용자 모드의 CPU 사용률 수치가 높다면 부하의 원인은 CPU 자체의 리소스 부족이라고 판단할 수 있습니다.
I/O 바운드 인 경우
sar 명령어로 I/O 바운드한 시스템에서의 CPU 사용률을 확인해보겠습니다.
$ sar
00:00:01 CPU %user %nice %system %iowait %idle
00:10:01 all 0.14 0.00 17.50 22.88 59.07
00:20:01 all 0.15 0.00 16.36 22.85 61.33
00:30:01 all 0.13 0.00 19.51 18.53 61.54
00:40:01 all 0.15 0.00 15.55 19.45 76.33
위의 결과에서 %iowait 은 I/O 대기율을 나타냅니다.
Load Average 가 높고 I/O 대기율이 상대적으로 높은 경우 부하의 원인은 I/O 에 있다고 판단할 수 있으며, 이때에는 I/O 관련하여 더 자세한 지표인 메모리 사용률이나 프로세스 별 스왑 발생 상황 등을 더 자세히 살펴본 후 적절히 대응할 수 있습니다.
멀티코어 CPU 에서 CPU 바운드와 I/O 바운드 의 경우
점점 CPU 가 발전하면서, 최근의 CPU 는 대부분 멀티코어로 구성됩니다. 이러한 경우에 CPU, I/O 바운드 한 경우 싱글코어 CPU 와 달리 어떤 차이점이 있을까요? 간단히 살펴보겠습니다.
멀티코어 CPU 에서 CPU 바운드 인 경우
$ sar
00:00:01 CPU %user %nice %system %iowait %idle
00:10:01 all 59.14 0.00 1.50 0.00 38.07
00:10:01 0 67.51 0.00 1.36 0.00 27.33
00:10:01 1 52.48 0.00 0.71 0.00 47.33
00:10:01 2 53.87 0.00 0.89 0.00 45.33
00:10:01 3 64.78 0.00 1.45 0.00 36.33
00:20:01 all 48.91 0.00 1.50 0.00 49.07
00:20:01 0 62.42 0.00 3.36 0.00 33.33
00:20:01 1 39.15 0.00 0.96 0.00 61.33
00:20:01 2 37.19 0.00 0.81 0.00 61.33
00:20:01 3 54.80 0.00 1.32 0.00 44.33
멀티코어 CPU 에서 CPU 바운드 인 경우, 각각의 CPU 코어에 %user 지표인 CPU 사용자 모드의 사용률이 높은 것 을 확인할 수 있습니다.
멀티코어 CPU 에서 I/O 바운드 인 경우
$ sar
00:00:01 CPU %user %nice %system %iowait %idle
00:10:01 all 0.10 0.00 18.50 22.31 58.87
00:20:01 all 0.14 0.00 15.50 22.78 61.31
00:30:01 all 0.17 0.00 17.50 18.81 61.07
위 처럼 I/O 대기율이 평균적으로 20% 전후 임을 확인 할 수 있습니다.
하지만, CPU의 코어 별로 I/O 대기율은 어떨까요?
$ sar
00:00:01 CPU %user %nice %system %iowait %idle
00:10:01 all 0.10 0.00 17.22 22.31 58.87
00:10:01 0 0.28 0.00 34.34 45.56 29.10
00:10:01 1 0.01 0.00 0.50 0.15 99.42
00:20:01 all 0.15 0.00 16.50 22.31 61.01
00:20:01 0 0.30 0.00 31.61 45.59 22.51
00:20:01 1 0.01 0.00 0.38 0.11 99.48
코어가 2개인 CPU의 경우, 위처럼 하나의 코어에 I/O wait 이 집중되는것을 확인할 수 있습니다.
이는 CPU 부하는 멀티코어 CPU에 고르게 분산할 수 있지만, I/O 부하의 경우 저장장치가 1개 라면 아무리 CPU 의 코어가 많아져도 저장장치로의 접근은 하나의 코어만 가능하므로 I/O 부하가 분산되지 않고 하나의 코어에 집중되게 됩니다.
이러한 I/O 부하의 편증 현상은 전체 CPU 코어로 봤을 때 에는 20% 정도의 I/O 부하가 걸리는 것 처럼 보이지만, 코어 별로 분석했을 때에는 하나의 코어에 40% 이상의 I/O 부하가 발생하는 편증이 나타납니다.
따라서 멀티코어의 경우, I/O 부하는 각 코어별로 개별적으로 확인 해 볼 필요성이 있습니다.
CPU 사용률이 계산되는 구체적인 원리
Load average 와 마찬가지로, 리눅스 커널에서 CPU 사용률을 계산하는 구체적인 과정을 알아두면 이해에 훨씬 도움이 될 것입니다.
항상 어떤 개념이든 코드 수준에서 이해한다면, 정말 그 개념을 확실하게 작동 원리까지 이해하고 있다고 말할 수 있는 것 같습니다.
리눅스 커널에서 CPU 사용률의 계산은 Load average 와 유사하게 타이머 인터럽트를 기반으로 커널 내부에서 수행됩니다.
Load average 는 타이머 인터럽트 시 대기중인 전체 프로세스 수 를 계산하는 반면, CPU 사용률 은 CPU 코어 별로 계산됩니다.
리눅스 커널에서는 프로세스 전환을 위해 각각의 프로세스가 생성된 이후로 CPU 를 어느정도 이용했는지를 프로세스 별로 기록하는데, 이를 프로세스 어카운팅 이라고 합니다.
프로세스 어카운팅을 기반으로 각각의 프로세스가 CPU 코어 별로 사용한 시간을 CPU 별 합계로 더하면, 각각의 CPU가 무엇에 얼만큼의 시간을 사용했는지를 알 수 있겠죠.
리눅스 커널의 kernel_stat.h 에 정의되어 있는 cpu 사용률 관련 구조체의 정의를 살펴보겠습니다.
// kernel_stat.h
enum cpu_usage_stat {
CPUTIME_USER,
CPUTIME_NICE,
CPUTIME_SYSTEM,
CPUTIME_SOFTIRQ,
CPUTIME_IRQ,
CPUTIME_IDLE,
CPUTIME_IOWAIT,
CPUTIME_STEAL,
CPUTIME_GUEST,
CPUTIME_GUEST_NICE,
NR_STATS,
};
struct kernel_cpustat {
u64 cpustat[NR_STATS];
};
struct kernel_stat {
unsigned long irqs_sum;
unsigned int softirqs[NR_SOFTIRQS];
};
위처럼 cpu_usage_stat 구조체에서 CPU 의 사용시간 등을 기록하고 있습니다.
각각의 프로세스의 사용 시간을 기록하는 프로세스 어카운팅 의 실제 처리 과정은 kernel / timer.c 에서 확인할 수 있습니다.
// timer.c
void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id(), system = user_tick ^ 1;
update_one_process(p, user_tick, system, cpu);
// CPU 사용자 모드
if (p->pid) {
if (--p->counter <= 0) {
p->counter = 0;
p->need_resched = 1;
}
if (p->nice > 0)
kstat.per_cpu_nice[cpu] += user_tick;
else
kstat.per_cpu_user[cpu] += user_tick;
kstat.per_cpu_system[cpu] += system;
}
// CPU 시스템 모드
else if (local_bh_count(cpu) || local_irq_count(cpu) > 1)
kstat.per_cpu_system[cpu] += system;
}
위처럼 CPU 가 사용자 모드인 경우와 시스템 모드인 경우를 분기하여 처리하는것 을 확인할 수 있습니다.
CPU가 사용자모드가 아닌 시스템모드로 작업중인 경우 Idle 상태나 시스템모드로 계산하고 있는 시간, I/O 를 기다리고 있는 시간 등이 있습니다.
이러한 과정을 통해서 CPU 별로 프로세스 어카운팅을 수행하여 CPU 사용률, I/O 사용률을 계산하고 측정할 수 있습니다.
정리하자면, Load Average 는 시스템의 전역적인 부하 를 나타내는 반면 CPU 사용률이나 I/O 대기율은 CPU 별로 저장된 계산 결과 입니다.
따라서 Load Average 는 시스템 전체에 걸리는 부하를 의미하여 더 자세한 정보를 알고 싶다면 CPU 와 I/O 사용률을 각각의 CPU 코어 마다 살펴보아야 합니다.
결론: 서버에 걸리는 부하를 추측하지 마라, 계측하라
지금까지 서버에 걸리는 부하의 종류와 원인, 정체와 리눅스 커널에서 부하를 계산하는 코드까지 모든 것 을 알아보았습니다.
물론 서버에 걸리는 부하의 종류와 원인 마다 다양한 대응 방법이 존재하겠지만, 모든 문제 해결의 첫 단계는 부하의 원인에 대한 정확한 측정에서 시작한다고 생각합니다.
문제에 대한 원인을 구체적이고 명확하게 안다면, 엔지니어는 언제나 해결 방법을 찾을 것 입니다.
이 글은 대규모 서비스를 지탱하는 기술 과 24시간 365일 서버/인프라를 지탱하는 기술 책을 읽고 혼자만 알기엔 너무 좋은 내용이 있어서 공유를 목적으로 작성하게 되었습니다.
위의 두 책에는 서버 부하 관련 내용 말고도 백엔드 개발자에게 피가되고 살이되는 서버 관련 지식과 수십년간 대규모 SNS 서비스의 서버, DB 를 직접 운영해오면서 겪은 노하우 들이 담겨있는 너무나도 좋은 책 입니다. 시간이 나신다면 읽어보시는걸 추천드립니다. 저는 내용이 너무 좋아서 2번씩 읽었네요.
오랜만에 긴 글을 작성하였네요! 항상 읽어주셔서 감사합니다.