Can Google ignore rel canonical? Yes, that can happen if Google believes the urls are not equivalent. Google’s John Mueller explained this in a recent webmaster hangout video and I have seen this happen a number of times while helping clients. My post below contains John’s comments along with a case study.

Last year I wrote a post explaining how Google can treat redirects to non-relevant urls as soft 404s. Google’s John Mueller explained that during a webmaster hangout video and it was great to hear confirmation from Google that it can happen. I’ve seen that first-hand many times and provided a case study of that happening in my post. You should check it out if you haven’t already.
The reason I bring up that post is because we have another statement by Google, and again, I’ve seen it happen first-hand a number of times. In Tuesday’s webmaster hangout video (at 33:31), Google’s John Mueller explained if you are canonicalizing one url to another, but the content is different on both pages, then Google’s algorithms might think you made a mistake by using rel canonical. And if that happens, then Google may simply index the url that’s being canonicalized anyway. Yes, read that again. You might be surprised to learn that.
I find a lot of people don’t know that rel canonical is a hint and not a directive. There’s an important distinction between the two. You can watch the video below of John explaining that rel canonical can be ingored (at 33:31 in the video):

When that happens, the pages you believe are not being indexed, actually are being indexed. It’s important to understand this, since you can end up with many more urls indexed than you intended to have indexed. And if those pages aren’t the greatest in the world, then they can impact your site quality-wise (as Google will evaluate all of your content for quality purposes). In addition, those pages can now be surfaced in the search results, and rank for queries that you didn’t intend them to rank for.
Here’s a quick graphic explaining what can happen indexation-wise:

Quick Case Study – Proof This Happens
It’s interesting timing for me personally, since I’m working on a crawl analysis and audit right now where this exact situation surfaced. It was clear during the audit that an excessive number of pages are being canonicalized to other urls, and not to equivalent content.
And quickly checking indexation via a site command for those pages revealed over one thousand urls still being indexed (even though they are being canonicalized to other urls on the site). In addition, I decided to filter landing pages in GSC and found the site command wasn’t accurate. There are actually MORE urls indexed that shouldn’t be.
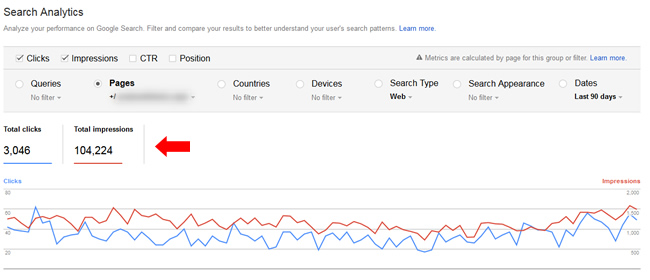
I exported the filtered list of landing pages via Analytics Edge and found 2,867 urls indexed that shouldn’t be (that are gaining impressions and clicks in the Google search results). Note, to learn how to use Analytics Edge to export all of your GSC data, follow my tutorial published on Search Engine Land.
Again, Google’s algorithms are simply believing the canonical setup was a mistake and choosing to ignore the canonical url tag on those urls.
Here are some screenshots of what I found:
Site command revealing 1,360 pages indexed that are canonicalized to other urls:
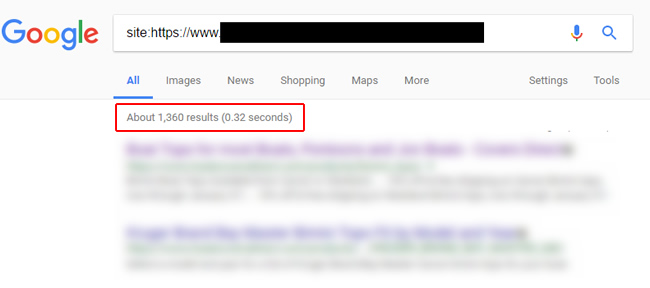
GSC shows that even more urls are receiving impressions and clicks (2,867):
And a crawl of those urls from GSC confirms they are being canonicalized to other urls:
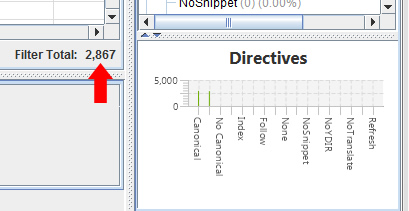
Therefore, the company I’m helping is having thousands of pages indexed that they didn’t intend to have indexed. I’m working with the company now on a new canonicalization strategy that will be much different than what they are doing now. It’s a great example of Google simply believing the canonical setup was a mistake and then indexing the urls anyway. Beware.
Options for SEOs
Some of you might be reading this post and feeling your blood pressure rise as you wonder how many pages on your site have been indexed that shouldn’t be. Well, that’s the point of my post! You should be wondering if your canonical setup is correct, how you can improve it, and how that can benefit your site SEO-wise.
When developing a canonicalization strategy, you have several options at your disposal. The exact setup depends on your own specific situation, but I’ll provide a quick set of bullets below (based on urls that have significantly different content). I highly recommend reviewing these options with your team and coming up with the optimal setup for your specific site.
Indexation Strategy Options When Content Differs Greatly:
- Noindex:
If the pages shouldn’t be indexed, and you definitely don’t want them indexed, then adding the meta robots tag using “noindex, follow” can work well. When using “noindex, follow”, you are telling Google to specifically not index the pages at hand. Noindex is a directive, so Google will follow the directive and not index those urls. And using “follow” enables Google to crawl the links on the page to discover content being linked to from the noindexed pages (while also passing signals to the destination urls). - Improve your canonicalization setup:
Rel canonical can work well, but only when it’s used properly. If you have content that’s duplicative, then by all means, use rel canonical. Then Google’s algorithms can consolidate indexing properties from the canonicalized pages and fold them together with the canonical url. It’s a great way to go, but only when used properly. But if you have pages with unique content, then ask yourself if those pages should be indexed. Do you want them ranking for targeted queries? Should users be able to find them from the search results? So on and so forth.Don’t simply canonicalize mass amounts of urls to other urls with greatly different content. That’s not really the intent of rel canonical anyway. It was introduced to help cut down on duplicate content and help webmasters point Google in the right direction about which urls to index and surface in the search results. As demonstrated above, Google’s algorithms can think the canonical setup is a mistake and simply ignore the canonical url tag.
Summary – Improving Canonicalization
Canonicalization can be a complex subject, especially for larger-scale sites with many moving parts. When I perform a crawl analysis and audit for clients, I’m always keeping a keen eye on the canonical setup and if Google is following that setup. If Google ignores a flawed setup, then that can impact indexation. And that means Google will use those additional urls when evaluating “quality”. In addition, Google might also surface the wrong urls in the search results without the webmaster even knowing that’s happening (if the problem sits unnoticed).
Therefore, it’s always important to review the signals you are sending Google, and then determine how Google is responding. If Google ends up ignoring your hints, then maybe those aren’t the greatest hints to be sending in the first place.
GG