
PredictionIO is an open source machine learning server for software developers to create predictive features, such as personalization, recommendation and content discovery. Building a production-grade engine to predict users’ preferences and personalize content for them used to be time-consuming. Not anymore with PredictionIO’s latest v0.7 release.
We are going to show you how PredictionIO streamlines the data process and make it friendly for developers and production deployment. A movie recommendation case will be used for illustration purpose. We want to offer “Top 10 Personalized Movie Recommendation” for each user. In addition, we also offer “If you like this movie, you may also like these 10 other movies….”.
Prerequisite
First, let’s explain a few terms we use in PredictionIO.
Apps
Apps in PredictionIO are not apps with program code. Instead, they correspond to the software application that is using PredictionIO. Apps can be treated as a logical separation between different sets of data. An App can have many Engines, but each Engine can only be associated with one App.
Engines
Engines are logical identities that an external application can interact with via the API. There are two types of Engines as of writing: item-recommendation, and item-similarity. Each Engine provide unique settings to meet different needs. An Engine may have only one deployed Algorithm at any time.
Algorithms
Algorithms are actual computation code that generates prediction models. Each Engine comes with a default, general purpose Algorithm. If you have any specific needs, you can swap the Algorithm with another one, and even fine tune its parameters.
Getting Hands-on
Preparing the Environment
Assuming a recent 64-bit Ubuntu Linux is installed, the first step is to install Java 7 and MongoDB. Java 7 can be installed by sudo apt-get install openjdk-7-jdk. MongoDB can be installed by following the steps described in Install MongoDB on Ubuntu.
Note: any recent 64-bit Linux should work. Distributions such as ArchLinux, CentOS, Debian, Fedora, Gentoo, Slackware, etc should all work fine with PredictionIO. Mac OS X is also supported.
Java 7 is required to run PredictionIO and its component Apache Hadoop. Apache Hadoop is optional since PredictionIO 0.7.0.
MongoDB 2.4.x is required for PredictionIO to read and write behavioral data and prediction model respectively.
Installing PredictionIO and its Components
To install PredictionIO, simply download a binary distribution and extract it. In this article, we assume that PredictionIO 0.7.0 has been installed at /opt/PredictionIO-0.7.0. When relative paths are used later in this article, they will be relative to this installation path unless otherwise stated.
The installation procedure is outlined in Installing PredictionIO on Linux.
To start and stop PredictionIO, you can use bin/start-all.sh and bin/stop-all.sh respectively.
Fine Tuning Apache Hadoop (Optional)
PredictionIO relies on Apache Hadoop for distributed data processing and storage. It is installed at vendors/hadoop-1.2.1. The following outlines some optimization opportunities.
vendors/hadoop-1.2.1/conf/hdfs-site.xml
dfs.name.dir and dfs.data.dir can be set to point at a big and persistent storage. Default values usually point at a temporary storage (usually /tmp), which could be pruned by the OS periodically.
vendors/hadoop-1.2.1/conf/mapred-site.xml
mapred.tasktracker.map.tasks.maximum and mapred.tasktracker.reduce.tasks.maximum control the maximum number of mapper and reducer jobs (data processing jobs). It is a good start to set the first value to be the number of CPU cores, and the second value to be half the first value. These should be reduced slightly to provide margin when you serve prediction in production settings if you do not run Hadoop on a separate machine.
mapred.child.java.opts controls the Java Virtual Machine options for each mapper and reducer job. It usually is a good idea to reserve a good amount of memory even when all mapper and reducer jobs are running. If you have a maximum of 4 mappers and 2 reducers, a 1GB heap space (-Xmx1g) for each of them (a total of 6GB max) would be reasonable if your machine has more than 10GB of RAM.
io.sort.mb controls the size of the internal sort buffer and is usually set to half of the child’s heap space. If you have set to 1GB above, this could be set to 512MB.
Creating an App in PredictionIO
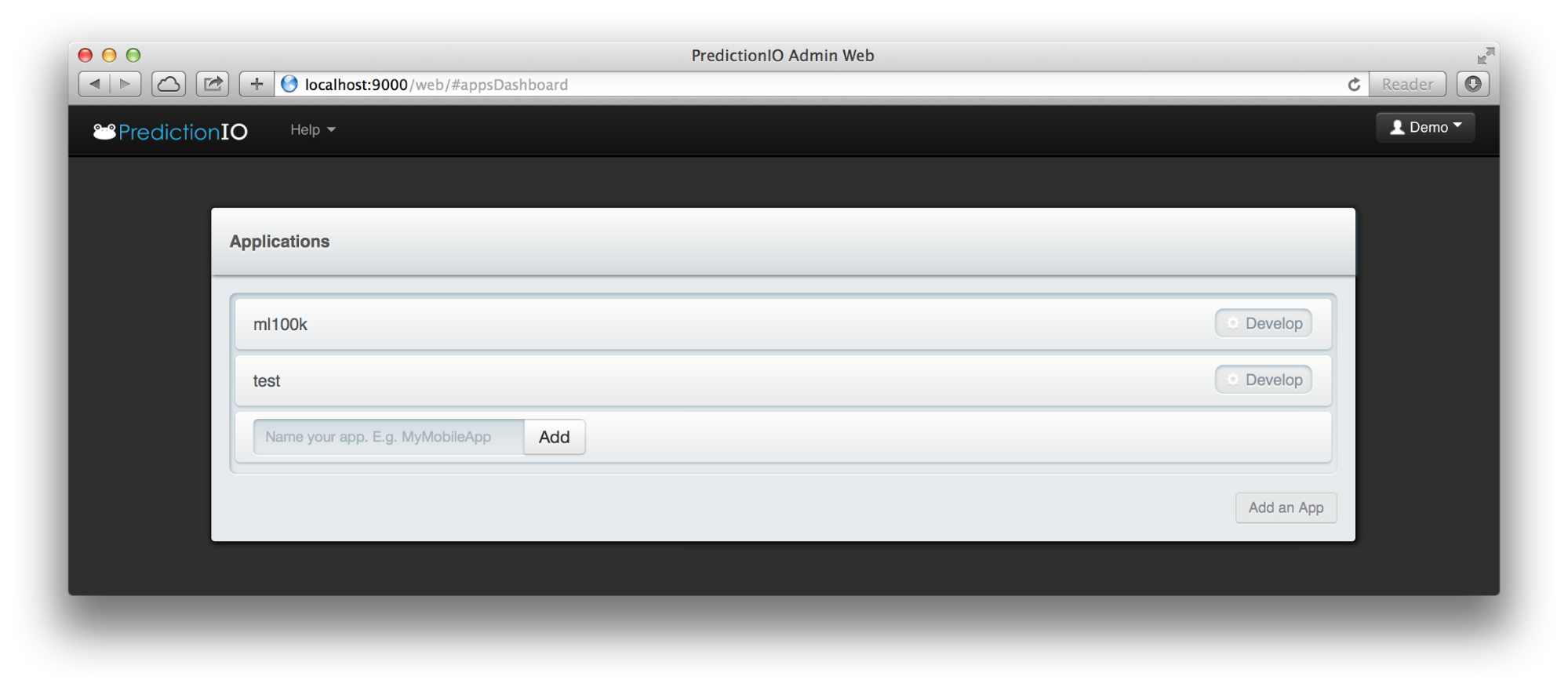
This can be done by logging in PredictionIO’s web UI located at port 9000 on the server.
The following is the first screen after logging in and clicking on the “Add an App” button. To add an app, simply input the app’s name and click “Add”.
Importing Data to PredictionIO
Before importing data, the app key of the target app must be obtained. This was done by clicking on “Develop” next to an app. The screen below is what can be seen afterwards.
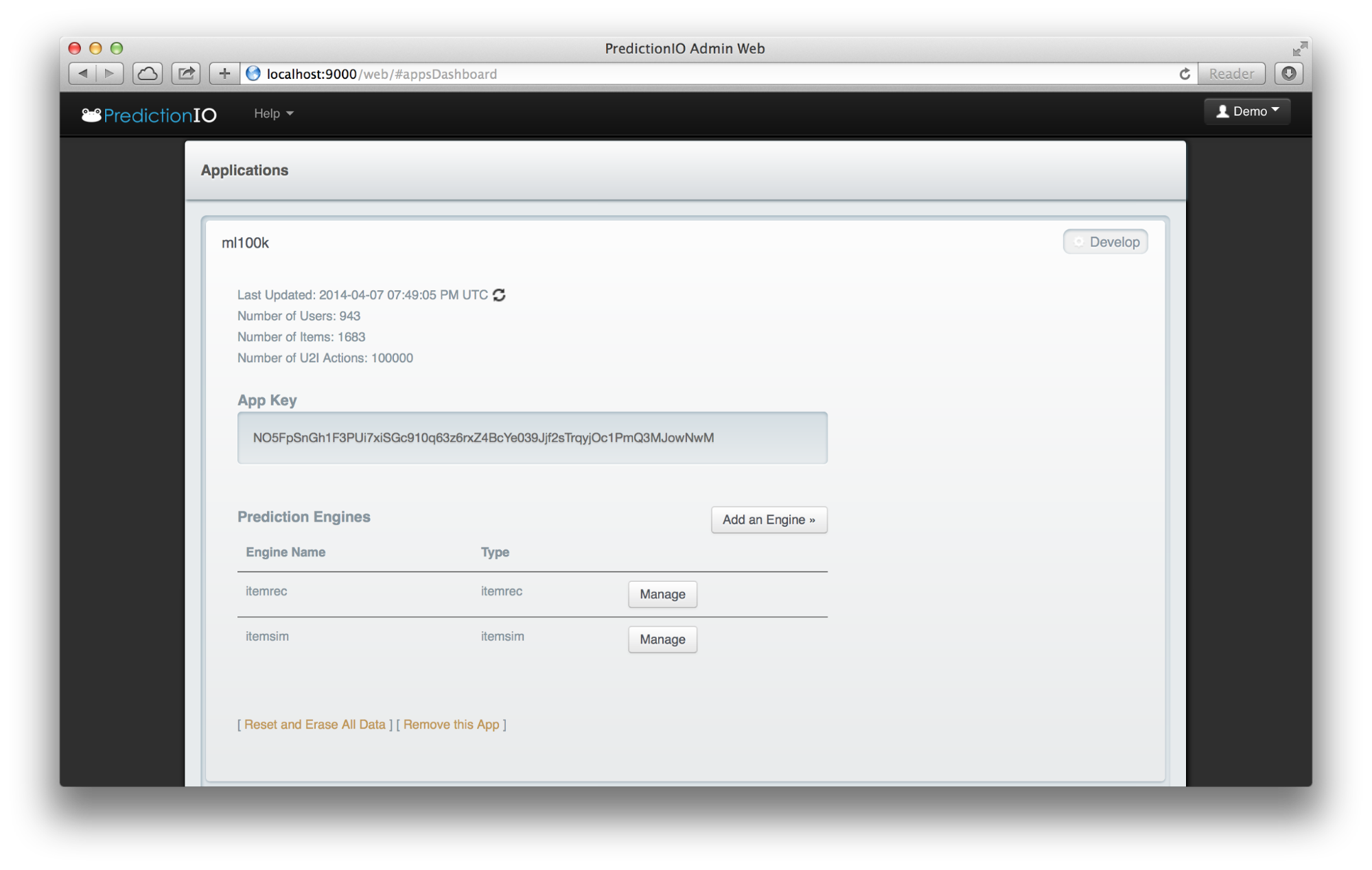
The app key for the “ml100k” app is NO5FpSnGh1F3PUi7xiSGc910q63z6rxZ4BcYe039Jjf2sTrqyjOc1PmQ3MJowNwM, as shown above. The app key is unique and your app key should be different.
To parse the MovieLens 100k data set and import to PredictionIO, one can use the import_ml.rb Gist. It requires the PredictionIO Ruby gem, which can be installed by sudo gem install predictionio.
Importing the whole set of data is simple:
ruby import_ml.rb NO5FpSnGh1F3PUi7xiSGc910q63z6rxZ4BcYe039Jjf2sTrqyjOc1PmQ3MJowNwM u.data
u.data is a file from the MovieLens 100k data set, which can be obtained from the GroupLens web site.
Adding Engines
Two engines can be added by simply clicking on the “Add an Engine” button. In our case, we have added “itemrec” and “itemsim” engines. Once they are added, they will commence training automatically with a default hourly schedule.
Getting Prediction Results
At the moment, you may access prediction results from these two sample URLs (API server at port 8000):
“Top 10 Personalized Movie Recommendation”:
http://localhost:8000/engines/itemrec/itemrec/topn.json?pio_appkey=NO5FpSnGh1F3PUi7xiSGc910q63z6rxZ4BcYe039Jjf2sTrqyjOc1PmQ3MJowNwM&pio_n=10&pio_uid=1
“If you like this movie, you may also like these 10 other movies….”:
http://localhost:8000/engines/itemsim/itemsim/topn.json?pio_appkey=NO5FpSnGh1F3PUi7xiSGc910q63z6rxZ4BcYe039Jjf2sTrqyjOc1PmQ3MJowNwM&pio_n=10&pio_iid=1
You may change the pio_uid and pio_iid parameters above to see results for other users/items. You are encouraged to take advantage of these endpoints to verify these results. You can also take advantage of our official and community-powered SDKs to simplify this process. Contributed SDKs are also available.
What’s News in PredictionIO v0.7
With the new extended support to GraphChi – a disk-based large-scale graph computation framework, developers can now evaluate and deploy algorithms in both GraphChi and Apache Mahout on one single platform!
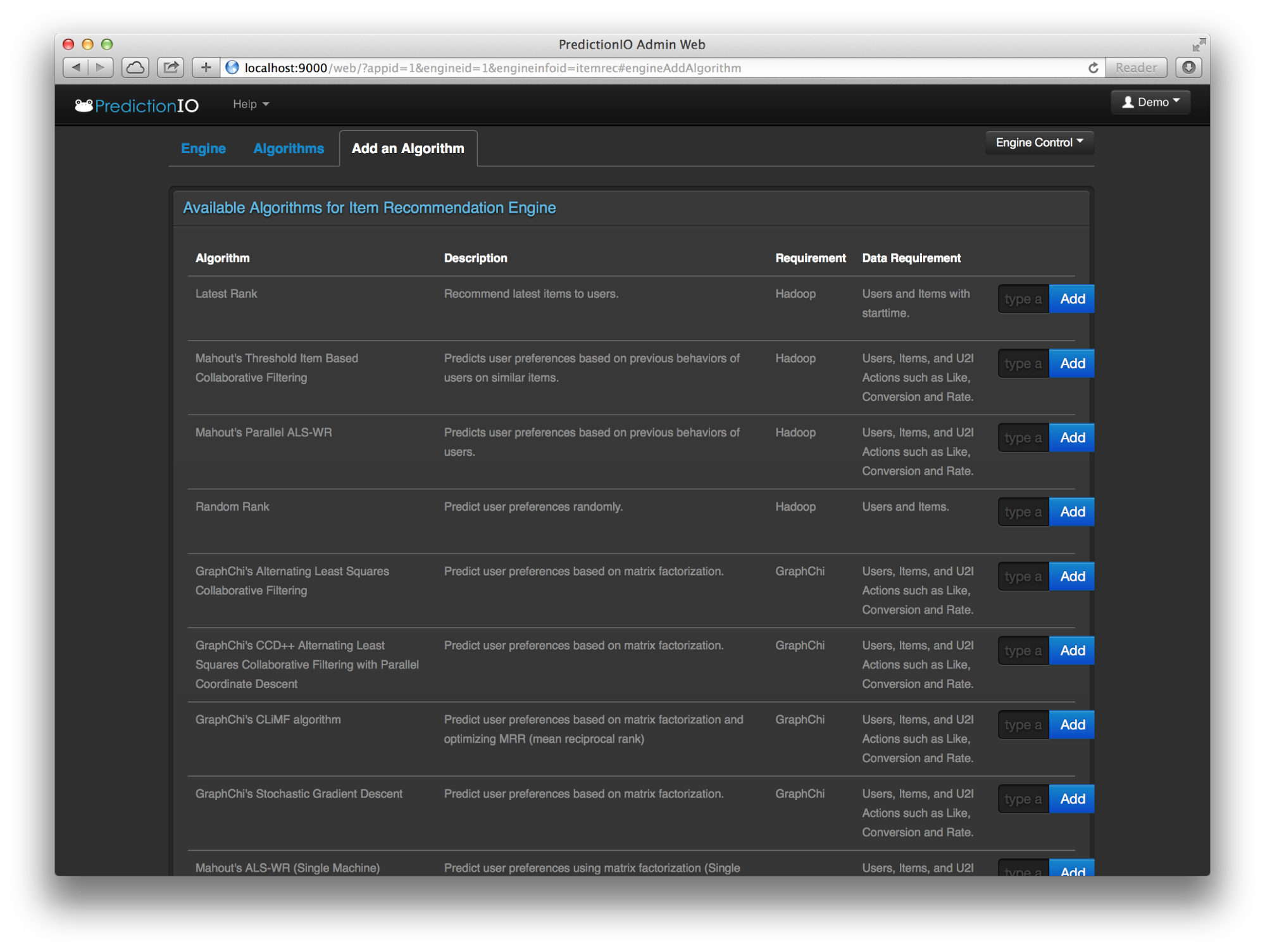
Enjoy!
About Donald Szeto
Applying 10+ years of experience in concurrent software and hardware engineering as a co-founder and CTO of PredictionIO, an open source machine learning server.
More articles by Donald Szeto…
About Robert Nyman [Editor emeritus]
Technical Evangelist & Editor of Mozilla Hacks. Gives talks & blogs about HTML5, JavaScript & the Open Web. Robert is a strong believer in HTML5 and the Open Web and has been working since 1999 with Front End development for the web - in Sweden and in New York City. He regularly also blogs at http://robertnyman.com and loves to travel and meet people.
8 comments